内存对齐
内存对齐原因
计算机是以字节(Byte)为单位划分的,理论上来说CPU可以访问任一编号的字节数据,但CPU的寻址其实是通过地址总线来访问内存的,CPU又分为32位和64位,32位的CPU一次可以处理4个字节(Byte)的数据,那么CPU实际寻址的步长就是4个字节,也就是只对编号是4的倍数的内存地址进行寻址。同理64位的CPU的寻址步长是8字节,只对编号是8的倍数的内存地址进行寻址,如下图所示是64位CPU的寻址示意图:
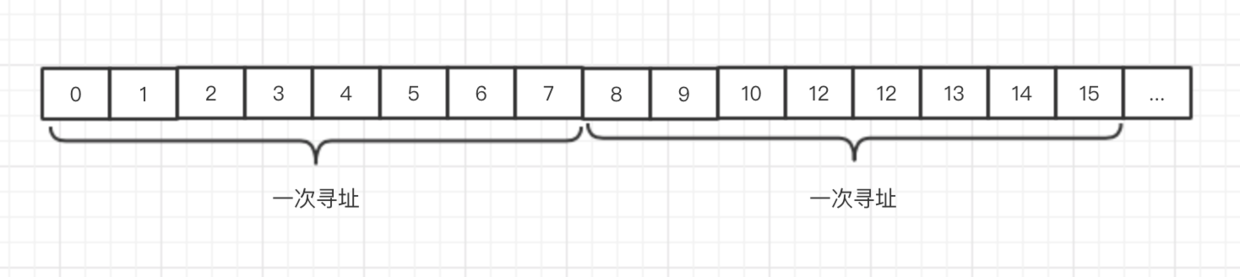
这样做可以实现最快速的寻址且不会遗漏一个字节,也不会重复寻址。
那么对于程序而言,一个变量的数据存储范围是在一个寻址步长范围内的话,这样一次寻址就可以读取到变量的值,如果是超出了步长范围内的数据存储,就需要两次寻址读取再进行数据的拼接,效率明显降低了。例如一个double类型的数据在内存中占8个字节,如果地址是8,那么好办,一次寻址就可以了,如果是20就需要进行两次寻址了。这样就产生了数据对齐的规则,也就是将数据尽量存储在一个步长内,避免跨步长的存储,这就是内存对齐。在32位编译环境下默认4字节对齐,在64位编译环境下默认8字节对齐。
参考资料
https://juejin.cn/post/6844904034080391181
https://juejin.cn/post/6870162226032934926#heading-2
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至yj.mapple@gmail.com
文章标题:内存对齐
文章字数:417
本文作者:melonshell
发布时间:2020-11-21, 16:34:23
最后更新:2020-11-21, 16:49:02
原始链接:http://melonshell.github.io/2020/11/21/cpu_mem_align/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

