常用缓存淘汰算法LFU/LRU/ARC/FIFO/MRU
缓存算法是指令的一个明细表,用于决定缓存系统中哪些数据应该被清理,常见的类型包括LFU/LRU/ARC/FIFO/MRU。
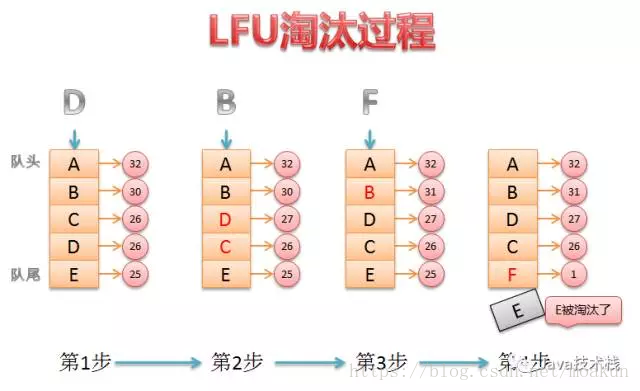
1 最不经常使用算法LFU:Least Frequency Used
基本思想:如果数据过去被访问多次,那么将来被访问的频率也更高。
注意LFU和LRU的区别,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数。
举个例子:
假设缓存大小为3,数据访问序列为set(2,2),set(1,1),get(2),get(1),get(2),set(3,3),set(4,4),则在set(4,4)时对于LFU算法应该淘汰(3,3),而LRU应该淘汰(1,1)。
那么LFU Cache应该支持的操作为:
- get(key):如果Cache中存在该key,则返回对应的value值,否则返回-1;
- set(key,value):如果Cache中存在该key,则重置value值;如果不存在该key,则将该key插入到Cache中,若Cache已满,则淘汰最少访问的数据;
为了能够淘汰最少使用的数据,LFU算法最简单的一种设计思路就是:利用一个数组存储数据项,用hashmap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据。这样一来,在插入数据和访问数据的时候都能达到O(1)的时间复杂度,在淘汰数据的时候,通过选择算法得到应该淘汰的数据项在数组中的索引,并将该索引位置的内容替换为新来的数据内容即可,这样的话,淘汰数据的操作时间复杂度为O(n)。
另外还有一种实现思路就是利用小顶堆+hashmap,小顶堆插入、删除操作都能达到O(logn)时间复杂度,因此效率相比第一种实现方法更加高效。
命中率分析
一般情况下,LFU效率要优于LRU,且能够避免周期性或者偶发性的操作导致缓存命中率下降的问题,但LFU需要记录数据的历史访问记录,一旦数据访问模式改变,LFU需要更长时间来适用新的访问模式,即LFU存在历史数据影响将来数据的"缓存污染"问题。
LFU使用计数器来记录条目被访问的频率,通过使用LFU缓存算法,最低访问次数的条目首先被移除,此方法并不经常使用,因为它无法对一个拥有最初高访问率之后长时间没有被访问的条目缓存负责。
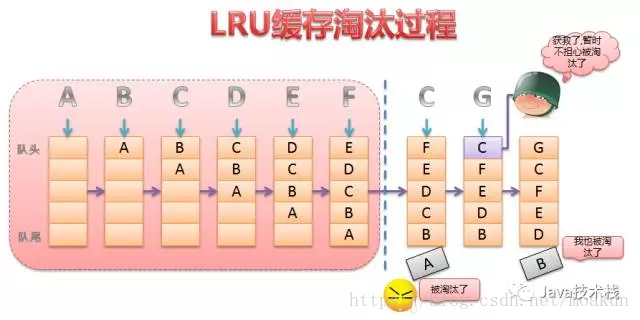
2 最近最少使用算法LRU:Least Recently used
基本思想:如果数据最近被访问过,那么将来被访问的几率也更高。
常见的实现:
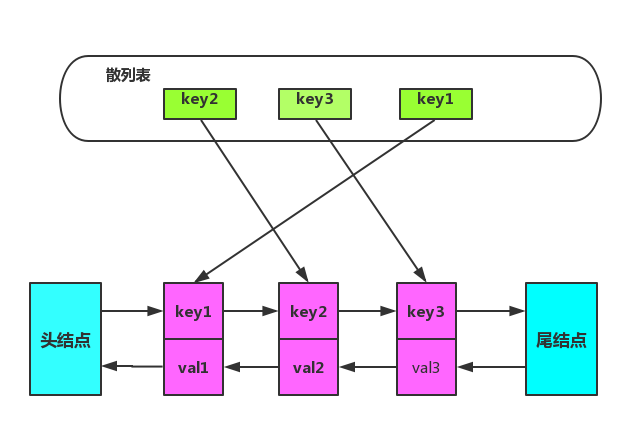
LRU算法需要添加头节点,删除尾结点,而链表添加节点,删除节点时间复杂度O(1),非常适合当做存储缓存数据容器,但不能使用普通的单向链表,普通单向链表有几点劣势:
- 每次获取任意节点数据,都需要从头结点遍历,导致获取节点复杂度为O(N);
- 移动中间节点到头结点,我们需要知道中间节点前一个节点的信息,单向链表不得不再次遍历获取;
针对以上问题,可以结合其他数据结构解决:使用散列表存储节点,获取节点的复杂度将会降低为O(1);节点移动问题可以在节点中再增加前驱指针,记录上一个节点信息,这样链表就从单向链表变成了双向链表。综上使用双向链表加散列表结合体,数据结构如图所示:
- 新数据插入到链表头部;
- 每当缓存命中,则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃;
命中率分析
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
MySQL InnoDB改进方案
将链表拆分成两部分:热数据区与冷数据区,如图所示:
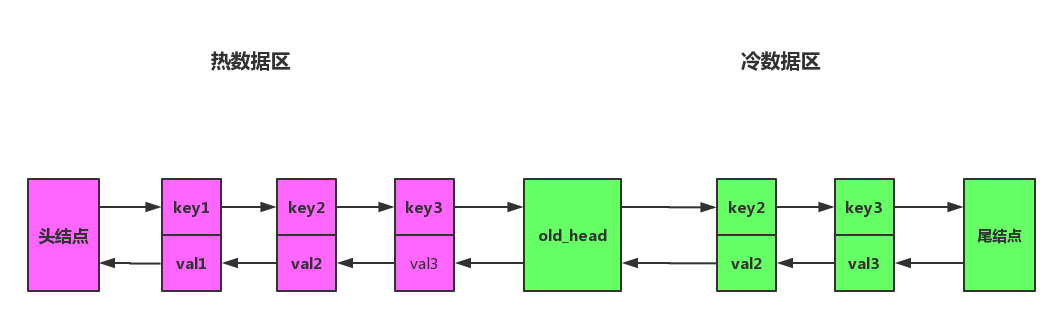
改进之后算法流程如下:
- 访问数据如果位于热数据区,与之前LRU算法一样,移动到热数据区的头结点;
- 插入数据时,若冷数据缓存已满,淘汰尾结点的数据,然后将数据插入冷数据区的头结点;
- 处于冷数据区的数据每次被访问需要做如下判断:(1) 若该数据已在缓存中超过指定时间,比如说1s,则移动到热数据区的头结点; (2) 若该数据存在时间小于指定的时间,则位置保持不变;
对于偶发的批量查询,数据仅仅只会落入冷数据区,然后很快就会被淘汰,热门数据区的数据将不会受影响,这样就解决了LRU算法缓存命中率下降的问题,其他改进方法还有LRU-K,2Q,LIRS算法。
LRU将最近使用的条目存放到靠近缓存顶部的位置,当一个条目被访问时,LRU将它放置到缓存的顶部,当缓存到达极限时,较早之前访问的条目将从缓存底部开始被移除。这里会使用到昂贵的算法,而且它需要记录年龄位来精确显示条目是何时被访问的,此外,当一个LRU缓存算法删除某个条目后,年龄位将随其他条目发生改变。
3 自适应缓存替换算法ARC
在IBM Almaden研究中心开发,这个缓存算法同时跟踪记录LFU和LRU,以及驱逐缓存条目,来获得可用缓存的最佳使用。
4 先进先出算法FIFO:First in First out
核心原则:如果一个数据最先进入缓存,则应该最早淘汰掉。
FIFO应该支持以下操作:
- get(key):如果Cache中存在该key,则返回对应的value值,否则,返回-1;
- set(key,value):如果Cache中存在该key,则重置value值;如果不存在该key,则将该key插入Cache,若Cache已满,则淘汰最早进入Cache的数据;
举个例子:
假如Cache大小为3,访问数据序列为:set(1,1),set(2,2),set(3,3),set(4,4),get(2),set(5,5),则Cache中的数据变化为:
(1,1) set(1,1)
(1,1) (2,2) set(2,2)
(1,1) (2,2) (3,3) set(3,3)
(2,2) (3,3) (4,4) set(4,4)
(2,2) (3,3) (4,4) get(2)
(3,3) (4,4) (5,5) set(5,5)
如何实现?
利用一个双向链表保存数据,当来了新的数据之后便添加到链表末尾,如果Cache存满数据,则把链表头部数据删除,然后把新的数据添加到链表末尾;
在访问数据的时候,如果Cache中存在该数据,则返回对应的value值,否则返回-1;
如果想提高访问效率,可以利用hashmap来保存每个key在链表中对应的位置;
FIFO是先进先出的数据缓存器,它与普通存储器的区别是没有外部读写地址线,这样使用起来非常简单,但缺点是只能顺序写入数据,顺序的读出数据,其数据地址由内部读写指针自动加1完成,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。
5 最近最常使用算法MRU
MRU算法最先移除最近最常使用的条目,MRU算法擅长处理条目越久,越容易被访问的情况。
6 LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法"缓存污染"的问题,其核心思想是将"最近使用过1次"的判断标准扩展为"最近使用过K次",常用实现如下:
- 数据第一次被访问,加入到访问历史列表;
- 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
- 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
- 缓存数据队列中被再次访问后,重新排序;
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即淘汰"倒数第K次访问离现在最久"的数据。
命中率分析
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。LRU-K降低了"缓存污染"带来的问题,命中率比LRU要高。
7 2Q:two queues
算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意不是缓存数据的)改为一个FIFO队列,即2Q有两个缓存队列:FIFO队列和LRU队列。
工作原理:
当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下:
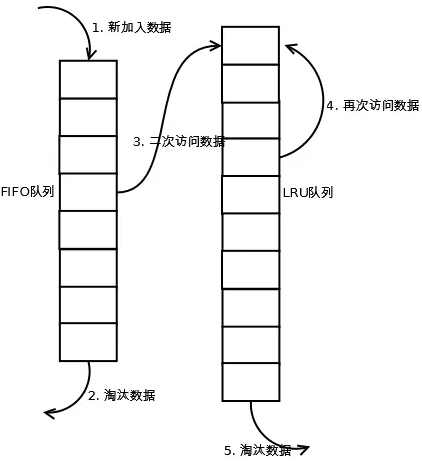
- 新访问的数据插入到FIFO队列;
- 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
- 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;
- 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
- LRU队列淘汰末尾的数据;
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至yj.mapple@gmail.com
文章标题:常用缓存淘汰算法LFU/LRU/ARC/FIFO/MRU
文章字数:2.6k
本文作者:melonshell
发布时间:2020-02-07, 18:48:19
最后更新:2020-02-07, 22:47:40
原始链接:http://melonshell.github.io/2020/02/07/ds_cache_eli/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

