缓存经典问题
1 缓存失效
缓存失效是由于大量key同时过期,请求直接从db加载导致db压力明显上升的问题。
缓存失效的问题主要是因为大量key有相同的过期时间导致,所以可以通过设计缓存过期时间,如过期时间 = base时间 + 随机时间让数据在未来一段时间内慢慢过期,避免瞬时同时过期。
2 缓存穿透
缓存穿透是由某些特殊请求持续访问系统不存在的key,直接加载到db,导致db压力上升,从而影响正常业务的现象。
对于缓存穿透可以通过如下两种方案解决:
- 查询这些不存在的数据时,第一次查询db,虽然没有查询到结果返回NULL,但仍记录这些key到缓存,并将这些key对应的value设置为一个特殊值。
warning: 这种方式会导致缓存中存在大量无用key的问题,对此可以采用将这些key设置一个比较短的过期时间或分配一个独立缓存专门存放这些key。对于独立缓存在读取时,先查询正常缓存是否命中,没有命中再查询独立缓存,如果独立缓存还没命中,再加载DB。 - 构建一个bloom filter缓存过滤器,记录全量数据,这样访问数据时,可以直接通过bloom filter判断这个key是否存在,如果不存在直接返回即可,根本不需要查询缓存或DB。
BloomFilter: 要缓存全量的key,这就要求全量的key数量不大,10亿条数据以内最佳,因为10亿条数据大概要占用1.2GB的内存,也可以用BloomFilter缓存非法key,每次发现一个key是不存在的非法key,就记录到 BloomFilter中,这种记录方案,会导致BloomFilter存储的key持续高速增长,为了避免记录key太多而导致误判率增大,需要定期清零处理。
3 缓存雪崩
缓存雪崩是指部分缓存节点不可用导致缓存服务整个系统不可用的情况,缓存雪崩按照缓存是否rehash(即是否漂移)分为两种情况:
- 不支持rehash导致的不可用,一般是由于缓存节点不可用,请求穿透到db导致db也过载,最终整个系统不可用;
- 支持rehash导致的不可用,大多跟流量洪峰有关,流量洪峰到达,引发部分缓存节点过载Crash,然后因rehash扩散到其他缓存节点,最终整个缓存体系异常。
对于缓存雪崩可以通过如下方案解决:
- 对于业务DB的访问添加读写开关,当发现DB请求变慢、阻塞、满请求超过阈值时,就关闭读开关,部分或所有读DB请求进行fail fast立即返回,待DB恢复后再打开读开关;
- 对缓存增加多个副本,缓存异常或请求miss后,再读取其他缓存或副本,而且多个缓存副本尽量部署在不同机架,从而确保在任何情况下,缓存系统都会正常对外提供服务;
- 对缓存体系进行实时监控,当请求访问的慢速比超过阈值时,及时告警,通过机器替换、服务替换进行及时回复;也可以通过多种自动故障转移策略,自动关闭异常接口、停止边缘服务、停止部分非核心功能措施,确保在极端场景下,核心功能的正常运行。
4 缓存不一致
同一份数据,可能会同时存在DB和缓存中,那就有可能发生DB和缓存的数据不一致,如果缓存有多个副本,多个缓存副本里的数据也可能会发生不一致现象。
不一致的问题大多跟缓存更新异常有关,比如更新DB后,写缓存失败,从而导致缓存中存的是老数据,另外,如果系统采用一致性hash分布,同时采用rehash自动漂移策略,在节点多次上下线后,也会产生脏数据。缓存有多个副本时,更新某个副本失败,也会导致这个副本的数据是老数据。
要尽量保持数据的一致性,这里也给出了3个方案,可以根据实际情况进行选择。
- 方案1:cache更新失败后,可以进行重试,如果重试失败,则将失败的key写入队列机服务,待缓存访问恢复后,将这些key从缓存删除。这些key在再次被查询时,重新从DB加载,从而保证数据的一致性。
- 方案2:缓存时间适当调短,让缓存数据及早过期后,然后从DB重新加载,确保数据的最终一致性;
- 方案3:不采用rehash漂移策略,而采用缓存分层策略,尽量避免脏数据产生。
5 并发竞争
数据并发竞争,是指在高并发访问场景,一旦缓存访问没有找到数据,大量请求会并发查询DB,导致DB压力大增的现象。
数据并发竞争,主要是由于多个进程/线程中,有大量并发请求获取相同的数据,而这个数据key因为正好过期、被剔除等原因在缓存中不存在,这些进程/线程没有任何协调,然后一起并发查询DB,请求那个相同的key,最终导致DB压力大增。
要解决并发竞争,有2种方案。
- 方案1:使用全局锁;
- 方案2:对缓存数据保持多个备份,即便其中一个备份中的数据过期或剔除了,还可以访问其他备份,从减少数据并发竞争的情况。
5 Hot Key
而在突发事件发生时,大量用户同时去访问热点信息,访问Hot Key,这个突发热点信息所在的缓存节点就很容易出现过载和卡顿现象,甚至会Crash。
如何发现及预估Hot Key?
- 提前评估出可能的Hot Key;
- 可以通过Spark,对应流任务进行实时分析,及时发现新发布的热点Key;
- 对于之前已发出的事情,逐步发酵为Hot Key的,则可以通过Hadoop对批处理任务离线计算,找出最近历史数据中的高频热key。
找到Hot Key后,可以有如下解决方案:
- 对Hot Key分散处理,比如一个Hot Key名字叫hotkey,可以被分散为hotkey#1,hotkey#2,hotkey#3,...,hotkey#n,这n个key分散存在多个缓存节点,然后client端请求时,随机访问其中某个后缀的hotkey,这样就可以把热key的请求打散,避免一个缓存节点过载,如下图:
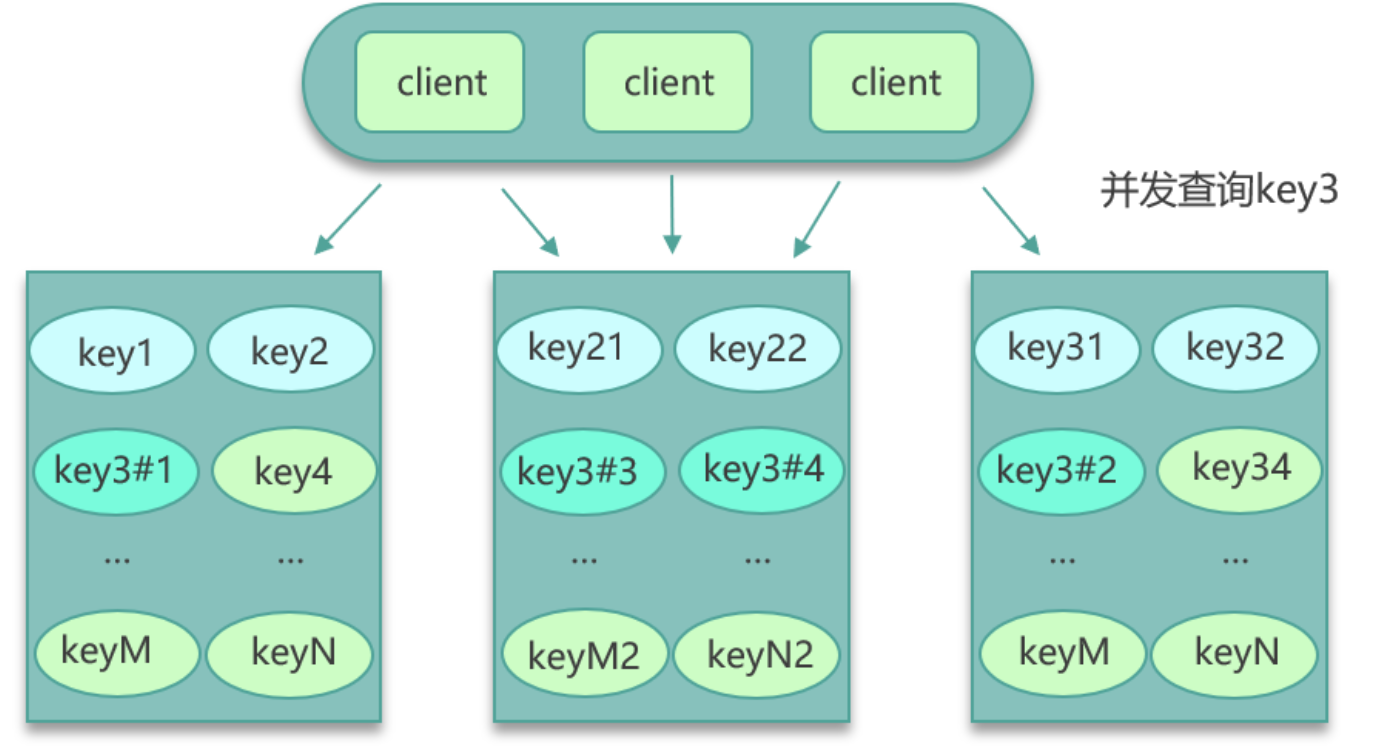
- key的名字不变,对缓存提前进行多副本 + 多级结合的缓存架构设计;
- 如果热key过多,还可以通过监控体系对缓存的SLA实时监控,通过快速扩容来减少热key冲击;
- 业务端还可以使用本地缓存,将这些热key记录在本地缓存,来减少对远程缓存的冲击;
6 Big Key
Big key也就是大key问题,大key,是指在缓存访问时,部分key的value比较大,读写、加载易超时的现象。对于大key,给出3中解决方案:
- 如果数据在Mc中,可以设计一个缓存阈值,当value的长度超过阈值,则对内容启用压缩,让KV尽量保持小的size,其次评估大key所占比例,在Mc启动之初,就立即预写足够数据的大key,让Mc预先分配足够多的trunk size较大的slab,确保后面系统运行时,大key有足够的空间来缓存。
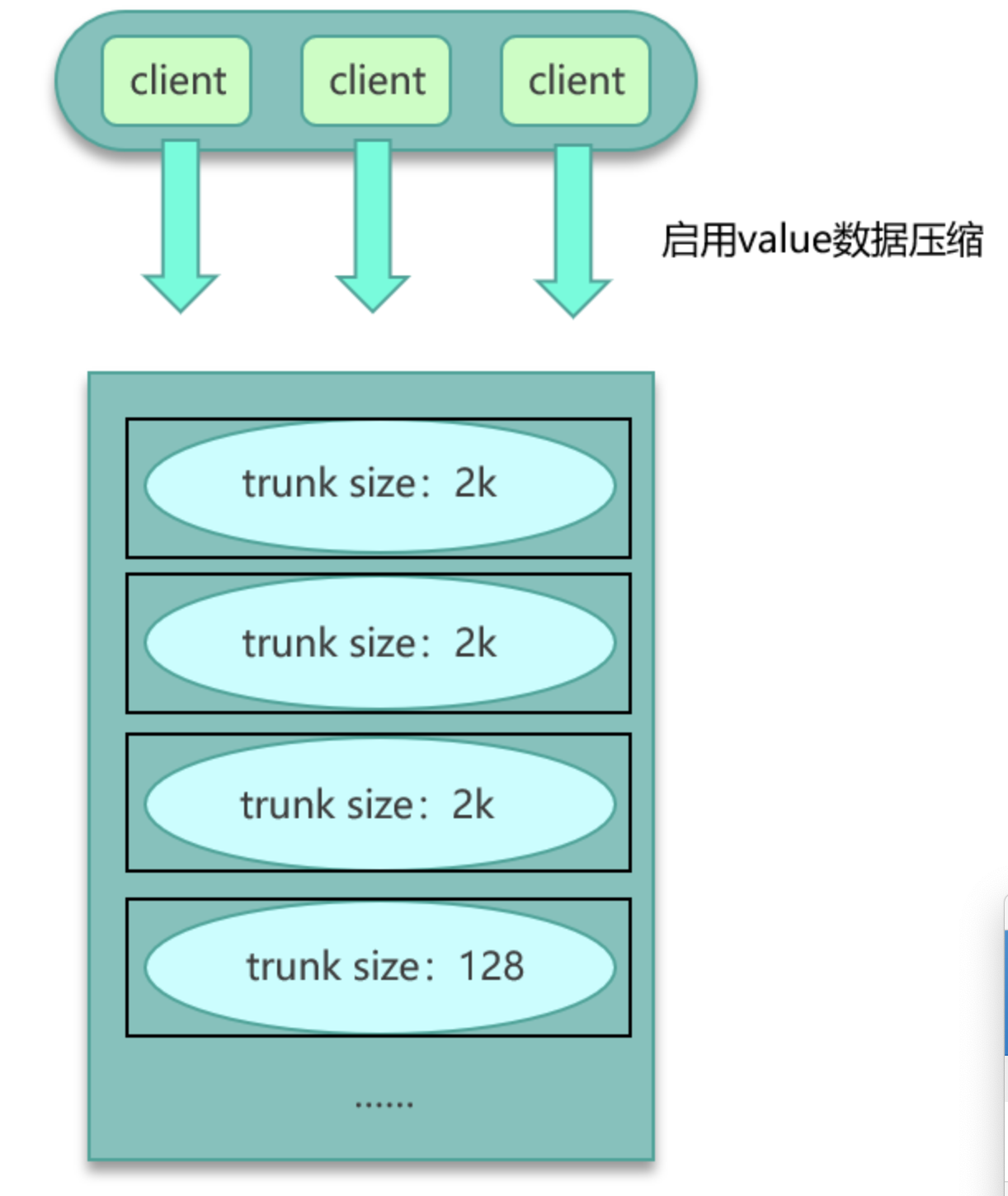
- 如果数据存在Redis中,比如业务数据存set格式,大key对应的set结构有几千几万个元素,这种写入Redis时会消耗很长的时间,导致Redis卡顿。此时,可以扩展新的数据结构,同时让client在这些大key写缓存之前,进行序列化构建,然后通过restore一次性写入,如下图:
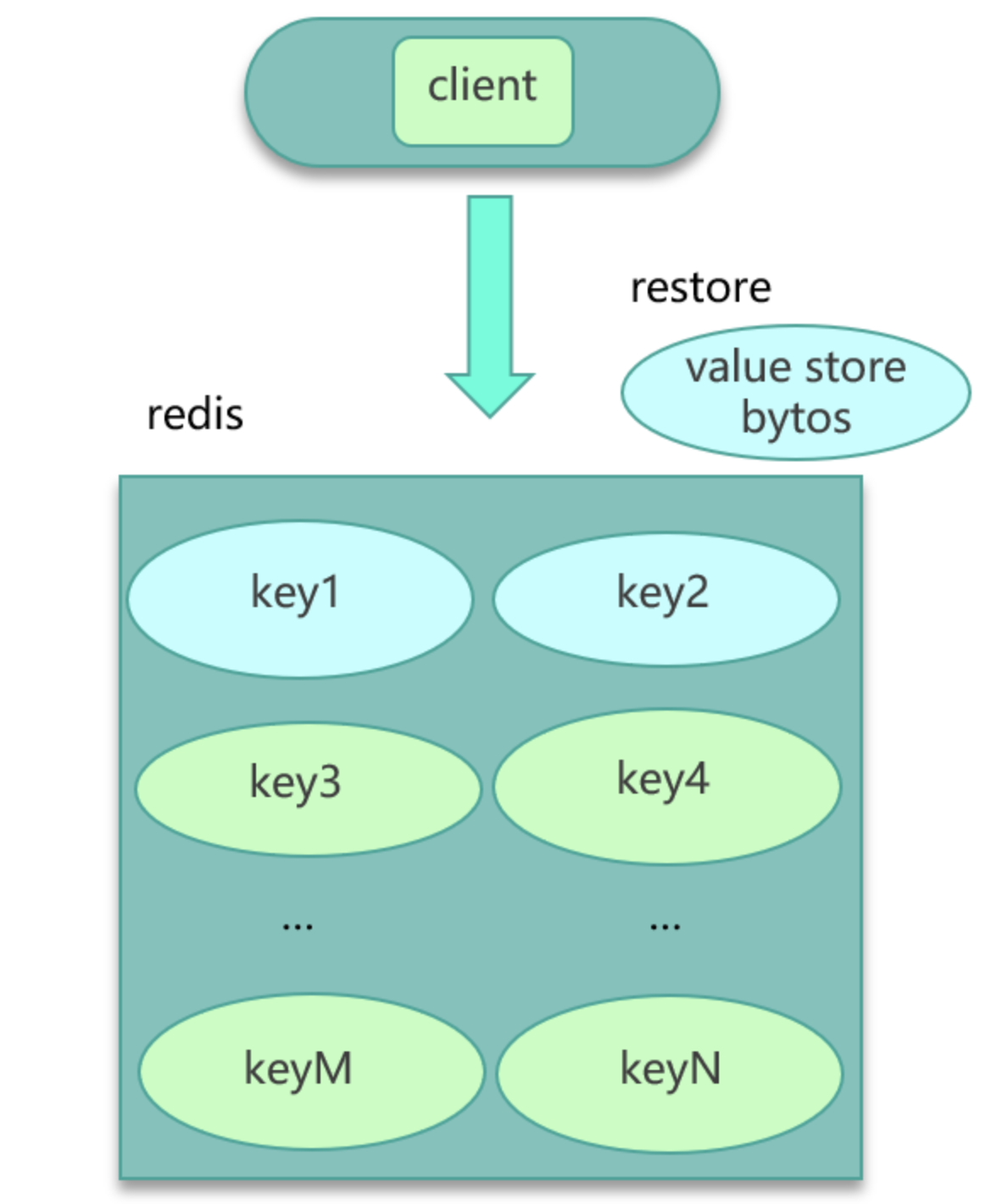
- 将大key分拆为多个key,尽量减少大key的数量。同时由于大key一旦穿透到DB,加载耗时很大,所以可以对这些大key进行特殊照顾,比如设置较长的过期时间;缓存内部在淘汰key时,同等条件下,尽量不淘汰这些大key。
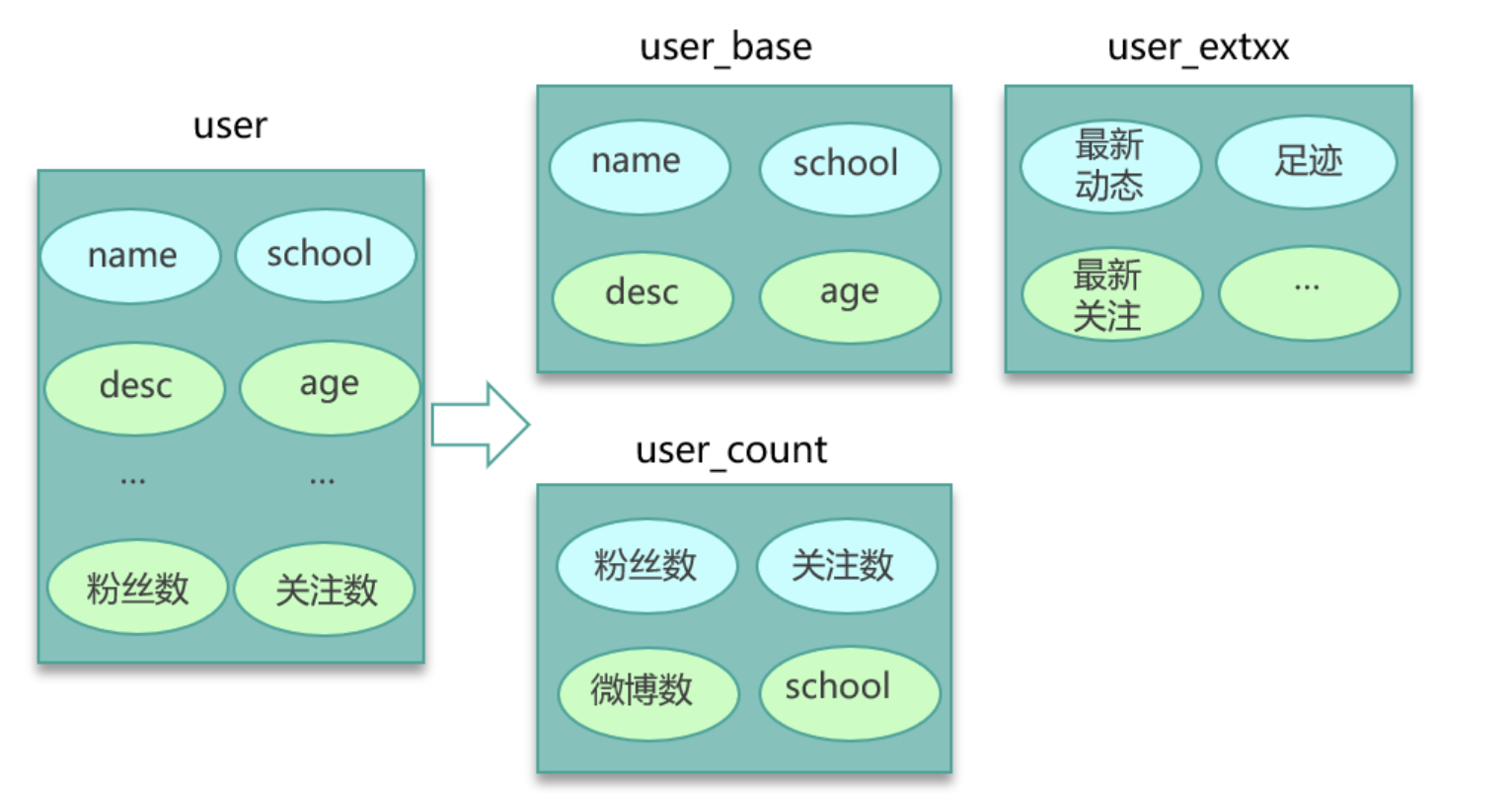
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至yj.mapple@gmail.com
文章标题:缓存经典问题
文章字数:2.2k
本文作者:melonshell
发布时间:2020-02-05, 14:13:11
最后更新:2020-02-05, 20:41:52
原始链接:http://melonshell.github.io/2020/02/05/tech11_cache1/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

