perf性能分析
1 介绍
Perf是用于软件性能分析的工具,通过Perf,应用程序可以利用PMU,tracepoint和内核中的特殊计数器进行性能统计。Perf不但可以分析应用程序的性能问题(per thread),也可以分析内核的性能问题,处理所有性能相关的事件:程序运行期间的硬件事件,如instructions retired ,processor clock cycles等;软件事件,如Page Fault和进程切换。
Perf可以计算每个时钟周期内的指令数IPC,IPC偏低表明代码没有很好地利用CPU;Perf还可以对程序进行函数级别采样,从而了解程序的性能瓶颈;Perf还可以替代strace,可以添加动态内核probe点,还可以做benchmark衡量调度器的好坏。
2 安装
1 二进制包安装
yum install perf
2 源码安装
- 查看内核版本:uname -a,Linux 10-62-81-197 3.10.107-1-tlinux2-0046
- 下载linux内核对应的源码:Linux源码
- 进入tools/perf目录,执行make&&make install
Linux目录:/usr/src/kernels/3.10.0-327.el7.x86_64/tools
3 预备知识
3.1 硬件特性之Cache
内存读写非常快,但还是无法和处理器的指令执行速度相比,为了从内存中读取指令和数据,处理器需要等待,从处理器的角度来看,这种等待非常漫长。Cache是一种SRAM,它的读写速度和处理器的速度相当,因此将常用的数据保存在Cache中,处理器便无需等待,Cache一般比较小,充分利用Cache是软件调优的重要部分。
3.2 硬件特性之流水线,超标量体系结构,乱序执行
提高性能最有效的方式之一就是并行,处理器在硬件设计时也尽可能地并行,比如流水线,超标量体系结构以及乱序执行。处理器处理一条指令需要分多个步骤完成,先取指令,然后完成运算,最后将计算结果输出到总线,在处理器内部,这可以看作一个三级流水线。
超标量(superscalar)指一个时钟周期发射(issue)多条指令的流水线机器架构,如Inte的Pentium处理器,内部有两个执行单元,在一个时钟周期内允许执行两条指令。
此外,在处理器内部不同指令所需要的处理步骤和时钟周期是不同的,如果严格按照程序的执行顺序执行,那么就无法充分利用处理器的流水线,因此指令有可能被乱序执行。
上述三种并行技术对所执行的指令有一个基本要求,即相邻的指令相互没有依赖关系。假如某条指令需要依赖前面一条指令的执行结果数据,那么pipeline便失去作用,因为第二条指令必须等待第一条指令完成。因此好的软件必须尽量避免生成这种代码。
3.3 硬件特性之分支预测
CPU采用流水线设计后分支指令对软件性能影响比较大,假设流水线有三级,处理器顺序读取指令,当前进入流水线的为分支指令,如果分支的结果是跳转到其他指令,那么处理器流水线预取的后续两条指令都降被丢弃,从而影响性能。为此,处理器提供了分支预测功能,根据同一条指令的历史执行记录进行预测,读取最可能的下一条指令。
分支预测对软件结构有一些要求,对于重复性的分支指令序列,分支预测能得到较好的预测结果,而对于类似switch case一类的程序结构,则往往无法得到理想的预测结果。
上面介绍的几种处理器特性对软件的性能有很大的影响,然而依赖时钟进行定期采样的profiler模式无法揭示程序对这些处理器硬件特性的使用情况,处理器厂商针对这种情况,在硬件中加入了PMU单元,即performance monitor unit。PMU允许软件针对某种硬件事件设置counter,此后处理器便开始统计该事件的发生次数,当发生次数超过counter内设置的值后则产生中断,比如cache miss达到某个值后,PMU便能产生相应的中断。捕获这些中断,就可以考察程序对这些硬件特性的利用效率了。
3.4 tracepoints
tracepoints是散落在内核源代码中的一些hook,可以在特定代码被运行时触发,这些特性可以被各种trace/debug工具使用,Perf就是利用了tracepoints。如果你想知道在程序执行期间内核内存管理模块的行为,就可以利用预埋在slab分配器中的tracepoint,当内核运行到这些tracepoint时,就会通知perf。perf将tracepoint产生的事件记录下来,生成报告,通过分析这些报告,我们就可以了解程序执行期间内核的种种细节,对性能症状做出更准确的诊断。
4 Perf的基本使用
Perf工作模式分为Counting Mode和Sampling Mode,Counting Mode将会精确统计一段时间内CPU相关硬件计数器数值的变化,为了统计用户感兴趣的事件,Perf Tool将设置性能控制相关的寄存器,这些寄存器的值将在监控周期结束后被读出,典型工具Perf Stat;Sampling Mode将以定期采样方式获取性能数据,PMU计数器将为某些特定事件配置溢出周期,当计数器溢出时,相关数据如 IP、通用寄存器、EFLAG 将会被捕捉到,典型工具Perf Record。
4.1 从一个例子开始
考查下面这个例子程序,其中函数longa()是个很长的循环,耗时较大,函数foo1和foo2分别调用这个函数10次和100次:
//t1
void longa()
{
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
int main(void)
{
foo1();
foo2();
}
g++ -o t1 -g t1.clonga()是程序的关键,只要提高它的速度就可以极大地提高程序的运行效率。
Perf基本原理是对被监测对象进行采样,最简单的情形是根据tick中断进行采样,即在tick中断内触发采样点,在采样点里判断程序当前的上下文。假如一个程序90%的时间都花费在函数foo()上,那么90%的采样点都应该落在函数foo()的上下文中,采样时间越长,上述推论越可靠。因此通过tick触发采样,我们就可以了解程序中哪些地方最耗时间。稍微扩展一下:
- 以时间点(如tick)作为事件触发采样可以获知程序运行的时间分布。
- 以cache miss事件触发采样可以知道cache miss的分布,即cache失效经常发生在哪些程序代码中。
查看perf帮助信息:
man perf/perf -h
man perf-stat/perf stat -h
man perf-top/perf top -h
man perf-record/perf record -h
man perf-report/perf report -h
man perf-list/perf list -h
4.2 Perf list
使用Perf list可以列出所有能够触发perf采样的事件:
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
…
cpu-clock [Software event]
task-clock [Software event]
context-switches OR cs [Software event]
…
ext4:ext4_allocate_inode [Tracepoint event]
kmem:kmalloc [Tracepoint event]
module:module_load [Tracepoint event]
workqueue:workqueue_execution [Tracepoint event]
sched:sched_{wakeup,switch} [Tracepoint event]
syscalls:sys_{enter,exit}_epoll_wait [Tracepoint event]不同的系统会有不同的结果:
List of pre-defined events (to be used in -e):
cpu-cycles OR cycles [Hardware event]
stalled-cycles-frontend OR idle-cycles-frontend [Hardware event]
stalled-cycles-backend OR idle-cycles-backend [Hardware event]
instructions [Hardware event]
cache-references [Hardware event]
cache-misses [Hardware event]
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cpu-clock [Software event]
task-clock [Software event]
page-faults OR faults [Software event]
minor-faults [Software event]
major-faults [Software event]
context-switches OR cs [Software event]
cpu-migrations OR migrations [Software event]
alignment-faults [Software event]
emulation-faults [Software event]
L1-dcache-loads [Hardware cache event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
L1-icache-prefetches [Hardware cache event]
L1-icache-prefetch-misses [Hardware cache event]
LLC-loads [Hardware cache event]
LLC-load-misses [Hardware cache event]
LLC-stores [Hardware cache event]
LLC-store-misses [Hardware cache event]
LLC-prefetches [Hardware cache event]
LLC-prefetch-misses [Hardware cache event]
dTLB-loads [Hardware cache event]
dTLB-load-misses [Hardware cache event]
dTLB-stores [Hardware cache event]
dTLB-store-misses [Hardware cache event]
dTLB-prefetches [Hardware cache event]
dTLB-prefetch-misses [Hardware cache event]
iTLB-loads [Hardware cache event]
iTLB-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
branch-load-misses [Hardware cache event]事件可以划分为三类:
- Hardware Event:由PMU硬件产生的事件,比如cache命中,用于了解程序对硬件特性的使用情况;
- Software Event:内核软件产生的事件,比如进程切换,tick数等;
- Tracepoint event:内核中静态tracepoint所触发的事件,这些tracepoint用来判断程序运行期间内核的行为细节,比如slab分配器的分配次数等;
- Hardware cache event:L1-dcache-load-misses、branch-loads等;
- Probe Event:用户自定义的时间,动态插入内核;
每一个事件都可以用于采样,并生成一项统计数据。
4.3 Perf stat
面对问题程序,最好采用自顶向下的策略,先整体看看程序运行时各种统计事件的大概,再针对某些方向深入细节。有些程序慢是因为计算量太大,多数时间都消耗在CPU计算上,这叫做CPU bound型;有些程序慢是因为过多的IO,此种情况CPU利用率并不高,这叫做IO bound型;对于CPU bound程序的调优和IO bound程序的调优是不同的。
Perf stat通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
perf stat ./t1
Performance counter stats for './t1':
266.995961 task-clock # 1.000 CPUs utilized
0 context-switches # 0.000 M/sec
0 CPU-migrations # 0.000 M/sec
259 page-faults # 0.001 M/sec
745,031,432 cycles # 2.790 GHz
<not counted> stalled-cycles-frontend
<not counted> stalled-cycles-backend
553,285,973 instructions # 0.74 insns per cycle
110,589,146 branches # 414.198 M/sec
16,657 branch-misses # 0.02% of all branches
0.266944803 seconds time elapsed上面告诉我们,t1是CPU bound型,因为task-clock为1。
对t1调试应该要找到热点(即最耗时的代码片段),再看看是否能够提高热点代码的效率。缺省情况下,除task-clock之外,perf stat还会给出其他几个常用的统计信息:
- task-clock-msecs:CPU利用率,此值越高说明程序的多数时间花费在CPU计算上而非IO;
- context-switches:进程切换次数,记录程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的;
- cache-misses:程序运行过程中总体的cache利用情况,如果该值过高,说明程序的cache利用不好;
- CPU-migrations:表示进程t1运行过程中发生了多少次CPU迁移,即被调度器从一个CPU转移到另外一个CPU上运行;
- cycles:处理器时钟,一条指令可能需要多个cycles;
- instructions:机器指令数目;
- IPC:instructions/cycles的比值,该值越大越好,说明程序充分利用了处理器的特性;
- cache-references:cache命中的次数;
- cache-misses:cache失效的次数;
通过-e选项,可以改变perf stat的缺省事件(perf list查看),perf stat -h查看帮助信息:
perf stat -p $pid -d #进程级别统计
perf stat -a -d sleep 5 #系统整体统计
perf stat -p $pid -e 'syscalls:sys_enter' sleep 10 #分析进程调用系统调用的情形
perf stat -a sleep 5 #收集整个系统的性能计数,持续5秒
perf stat -C 0 #统计CPU 0的信息-r参数指定重复执行次数:perf stat -r 5 ./t1。
4.4 Perf top
使用Perf stat的时候,往往已经有了一个优化目标,比如上述的t1,但有时候只是发现性能下降,并不清楚是哪个进程,此时需要一个类似top的命令,列出所有值得怀疑的进程,从中找到需要进一步审查的进程。Perf top用于实时统计当前系统的性能信息,该命令主要用于观察整个系统的当前状态,通过观察此命令的输出可以查看当前系统最耗时的内核函数或某个用户进程。
//t2
while(1) i++;
gcc -o t2 -g t1.cc 下面是perf top的可能输出:
PerfTop: 705 irqs/sec kernel:60.4% [1000Hz cycles]
--------------------------------------------------
sampl pcnt function DSO(Dynamic Shared Object)
1503.00 49.2% t2
72.00 2.2% pthread_mutex_lock /lib/libpthread-2.12.so
68.00 2.1% delay_tsc [kernel.kallsyms]
55.00 1.7% aes_dec_blk [aes_i586]
55.00 1.7% drm_clflush_pages [drm]
52.00 1.6% system_call [kernel.kallsyms]
49.00 1.5% __memcpy_ssse3 /lib/libc-2.12.so
48.00 1.4% __strstr_ia32 /lib/libc-2.12.so
46.00 1.4% unix_poll [kernel.kallsyms]
42.00 1.3% __ieee754_pow /lib/libm-2.12.so
41.00 1.2% do_select [kernel.kallsyms]
40.00 1.2% pixman_rasterize_edges libpixman-1.so.0.18.0
37.00 1.1% _raw_spin_lock_irqsave [kernel.kallsyms]
36.00 1.1% _int_malloc /lib/libc-2.12.so很容易发现t2是需要关注的可以程序,通过-e选项,可以列出造成其他事件的TopN个进程/函数,比如-e cache-miss,用于查看谁造成的cache miss最多。对于制定进程可以:perf top -p pid,perf top -h查看帮助。
perf top -p $pid -g #进程级别
perf top -g #系统整体在perf top界面按h键可以唤起帮助菜单,选中t2一行按a键(或者Enter键选择),即可启用Annotate注释功能,进一步查看当前符号。
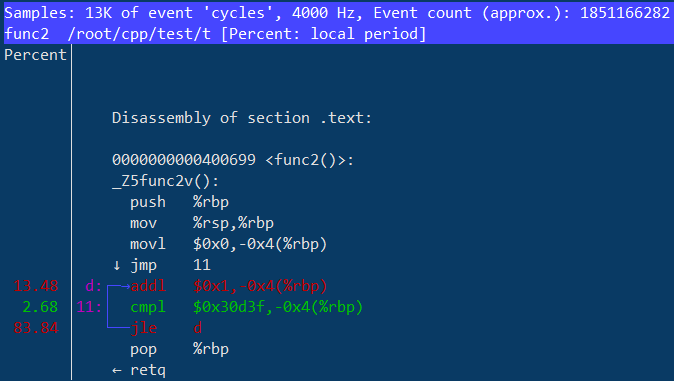
4.5 perf record和perf report
使用perf top和perf stat之后,对系统性能已经有了一个大致的了解,下面就需要进一步分析更细粒度的信息。perf record记录单个函数级别的统计信息,并使用perf report来显示统计结果。下面仍然以t1为例:
perf record -e cpu-clock ./t1
perf report //OR perf report -i
Output:
Events: 268 cpu-clock
99.63% t1 t1 [.] longa()
0.37% t1 [kernel.kallsyms] [k] perf_event_aux_ctx不出所料,longa()是消耗CPU最多的函数。查看更多帮助信息:perf record -h / perf report -h。
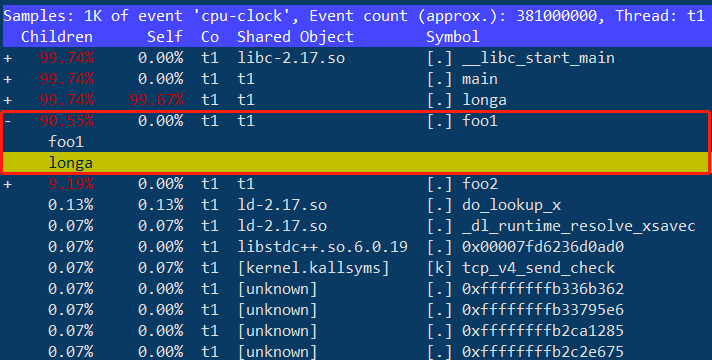
代码非常复杂,t1中的foo1()是一个潜在的优化对象,但上面无法发现foo1和foo2,更无法了解他们的区别,使用perf record的-g选项便可以得到需要的信息:
perf record -e cpu-clock -g ./t1
perf report -g
Output:
Samples: 1K of event 'cpu-clock', Event count (approx.): 398250000
Children Self Command Shared Object Symbol
+ 99.94% 99.75% t1 t1 [.] longa
+ 99.81% 0.00% t1 libc-2.17.so [.] __libc_start_main
+ 99.81% 0.00% t1 t1 [.] main
+ 90.65% 0.00% t1 t1 [.] foo1
+ 9.17% 0.00% t1 t1 [.] foo2
0.13% 0.13% t1 [kernel.kallsyms] [k] retint_careful
0.13% 0.00% t1 [unknown] [.] 0xffffffffb336b4ed
0.06% 0.06% t1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.06% 0.00% t1 [unknown] [.] 0xffffffffb3375df2
0.06% 0.00% t1 [unknown] [.] 0xffffffffb33796c8
0.06% 0.00% t1 [unknown] [.] 0xffffffffb2ca1285
0.06% 0.00% t1 [unknown] [.] 0xffffffffb2c2e675
0.06% 0.06% t1 ld-2.17.so [.] _dl_lookup_symbol_x
0.06% 0.00% t1 ld-2.17.so [.] _dl_sysdep_start
0.06% 0.00% t1 [unknown] [.] 0xffffffffb337832c
0.06% 0.00% t1 ld-2.17.so [.] dl_main
0.06% 0.00% t1 [unknown] [.] 0xffffffffb2ca0f05
0.06% 0.00% t1 ld-2.17.so [.] _dl_relocate_object
0.06% 0.00% t1 [unknown] [.] 0xffffffffb2d54d33
0.06% 0.00% t1 [unknown] [.] 0xffffffffb336a175通过对calling graph的分析,能很方便地看到90.65%的时间都花费在foo1()函数中,因为它调用了100次longa()函数,因此如果 longa()是个无法优化的函数,那么就应该考虑优化foo1,减少对longa()的调用次数。
perf record -p $pid -g -e cycles -e cs #进程采样
perf record -a -g -e cycles -e cs #系统整体采样可以上下键移动到foo1函数,回车,选择longa函数:
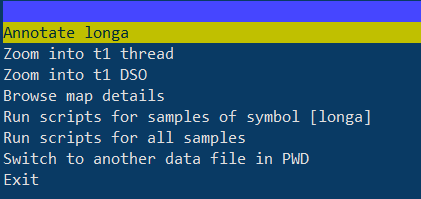
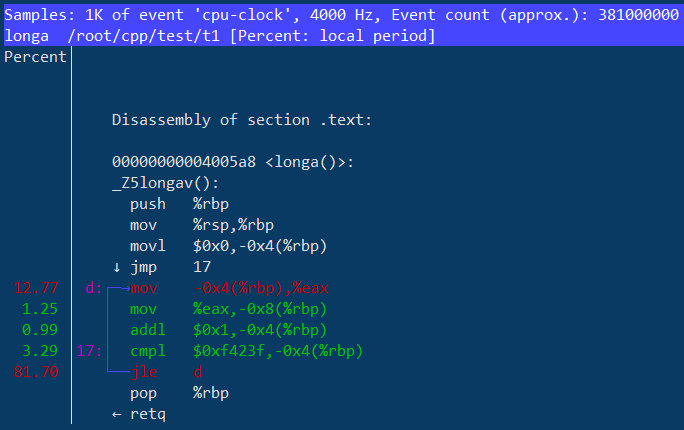
继续回车,这里有很多选项,我们选择Annotate longa查看汇编代码级的cpu-clock分布:
4.6 Perf script
读取Perf record结果:
-i, --input <file> input file name
-G, --hide-call-graph
When printing symbols do not display call chain
-F, --fields <str> comma separated output fields prepend with 'type:'. Valid types: hw,sw,trace,raw. Fields: comm,tid,pid,time,cpu,event,trace,ip,sym,dso,addr,symoff,period
-a, --all-cpus system-wide collection from all CPUs
-S, --symbols <symbol[,symbol...]>
only consider these symbols
-C, --cpu <cpu> list of cpus to profile
-c, --comms <comm[,comm...]>
only display events for these comms
--pid <pid[,pid...]>
only consider symbols in these pids
--tid <tid[,tid...]>
only consider symbols in these tids
--time <str> Time span of interest (start,stop)
--show-kernel-path
Show the path of [kernel.kallsyms]
--show-task-events
Show the fork/comm/exit events
--show-mmap-events
Show the mmap events
--per-event-dump Dump trace output to files named by the monitored events输出样式:
...
swapper 0 [000] 222998.934740: 1 cycles:
7fff81062eaa native_write_msr_safe ([kernel.kallsyms])
7fff8100ae75 __intel_pmu_enable_all.isra.12 ([kernel.kallsyms])
7fff8100aef0 intel_pmu_enable_all ([kernel.kallsyms])
7fff810077bc x86_pmu_enable ([kernel.kallsyms])
7fff81172817 perf_pmu_enable ([kernel.kallsyms])
7fff81173701 ctx_resched ([kernel.kallsyms])
7fff81173870 __perf_event_enable ([kernel.kallsyms])
7fff8116dfdc event_function ([kernel.kallsyms])
7fff8116eaa4 remote_function ([kernel.kallsyms])
7fff810fbb5d flush_smp_call_function_queue ([kernel.kallsyms])
7fff810fc233 generic_smp_call_function_single_interrupt ([kernel.kallsyms])
7fff810505c7 smp_call_function_single_interrupt ([kernel.kallsyms])
7fff8169a41d call_function_single_interrupt ([kernel.kallsyms])
7fff810367bf default_idle ([kernel.kallsyms])
7fff81037106 arch_cpu_idle ([kernel.kallsyms])
7fff810ea2a5 cpu_startup_entry ([kernel.kallsyms])
7fff81676fe7 rest_init ([kernel.kallsyms])
7fff81b0c05a start_kernel ([kernel.kallsyms])
7fff81b0b5ee x86_64_start_reservations ([kernel.kallsyms])
7fff81b0b742 x86_64_start_kernel ([kernel.kallsyms])
...4.7 火焰图
火焰图是一种剖析软件运行状态的工具,它能够快速的将频繁执行的代码路径以图表的形式展现给用户,根据Brendan Gregg的介绍,常用的火焰图包括以下5种:
- CPU
- Memory
- Off-CPU
- Hot/Cold
- Differential
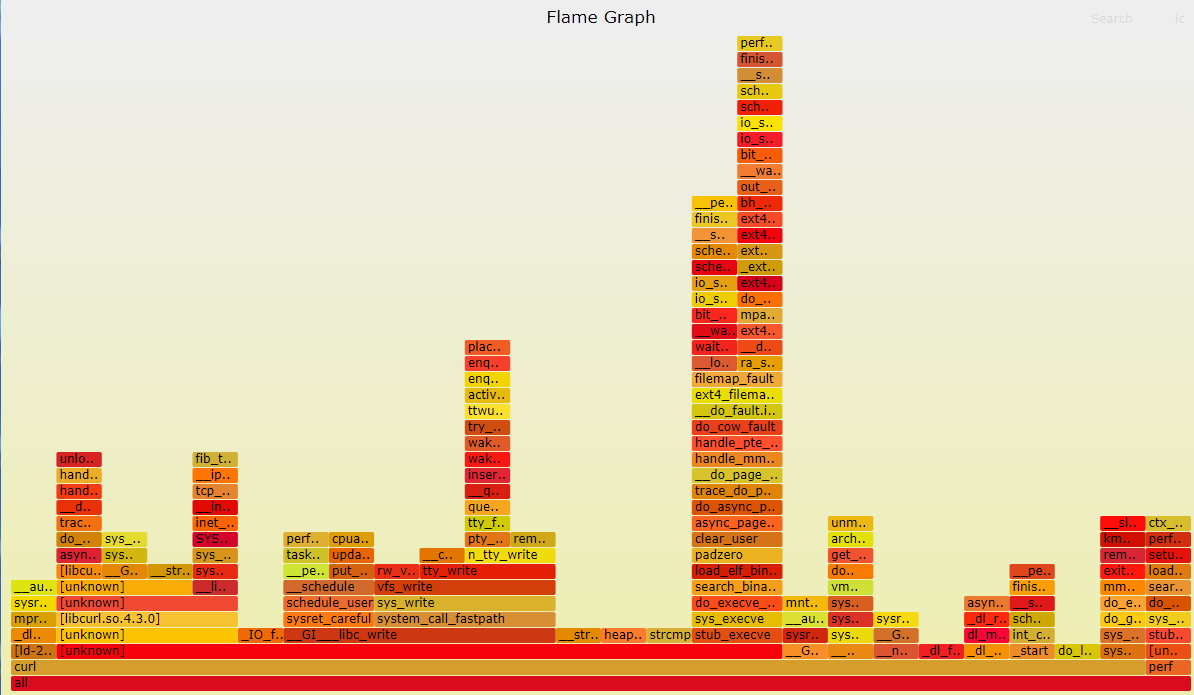
4.7.1 CPU火焰图
CPU火焰图反映了一段时间内用户程序在CPU上运行的热点,其绘制原理是对Perf采集到的samples进行解析,对函数调用栈进行归纳合并,以柱状图的形式呈现给系统管理员。
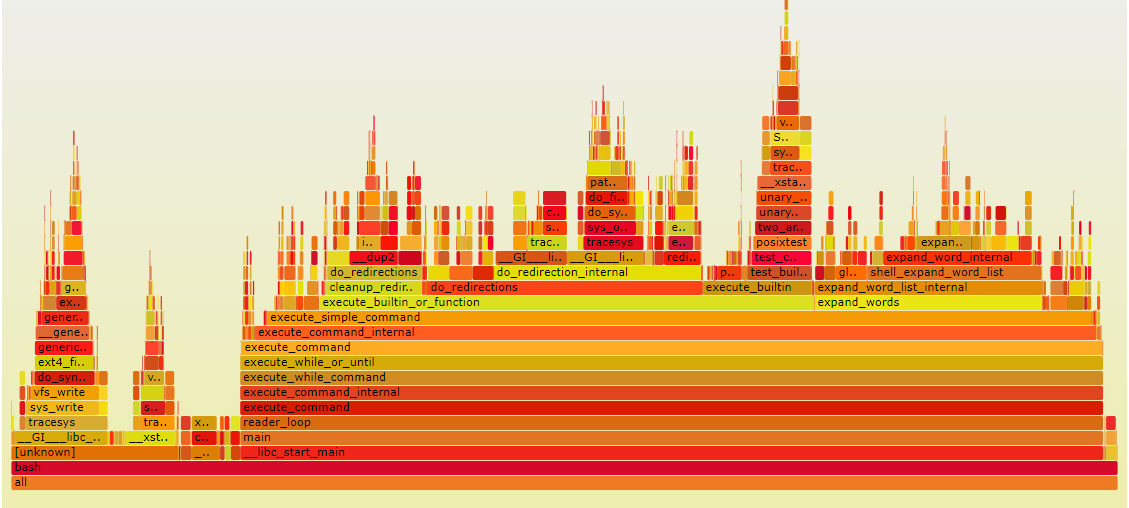
图片描述
- 每个长方块代表了函数调用栈中的一个函数,即为一层堆栈的内容;
- Y轴显示堆栈深度,顶层方块表示CPU上正在运行的函数,下面的函数即为主调;
- X轴的宽度代表被采集的sample数量,越宽表示采集到的越多;
绘制原理
火焰图的绘制需要Perf Tool以及一些Perl脚本的辅助。
1) 采集样本
通过Perf Record收集CPU热点样本原始文件。
2) 解析样本
通过Perf Script解析样本原始文件,得到样本对应的堆栈。
3) 绘制火焰图
统计堆栈中函数出现的频率,并以此绘制火焰图。
4.7.2 Off-CPU火焰图
On CPU火焰图可反映某时刻CPU的运行热点,然而它却留下了Off-CPU的问题:某些程序为何进入睡眠状态?睡眠时长有多久?
下图是一张Off-CPU时间图,展示了一个由于系统调用而被阻塞的应用线程的运行情况。
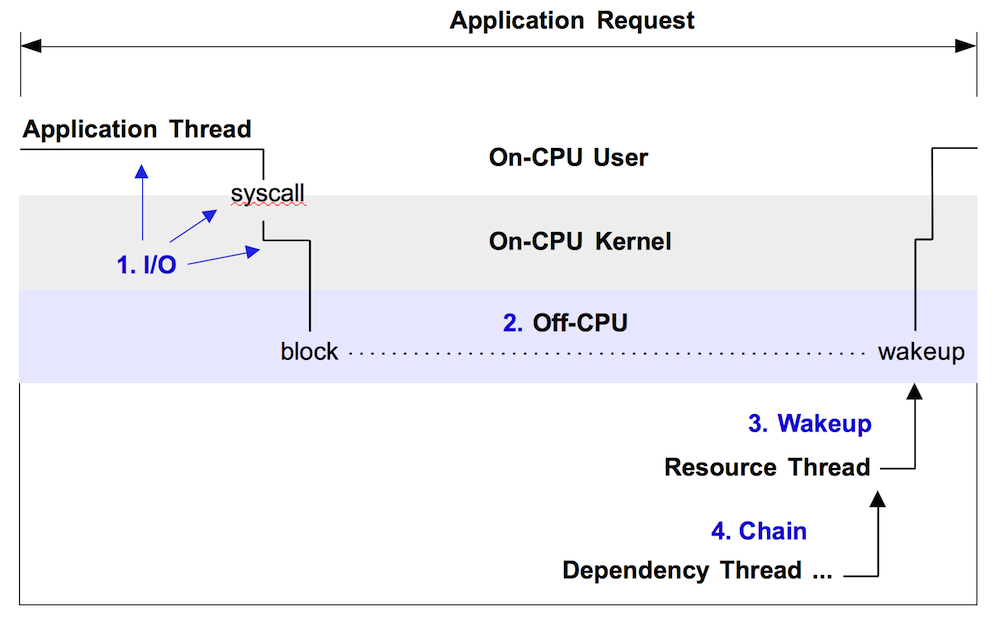
从图中我们可以看出应用线程长时间被阻塞在Off-CPU状态,而这段时间则无法通过On-CPU火焰图反映。
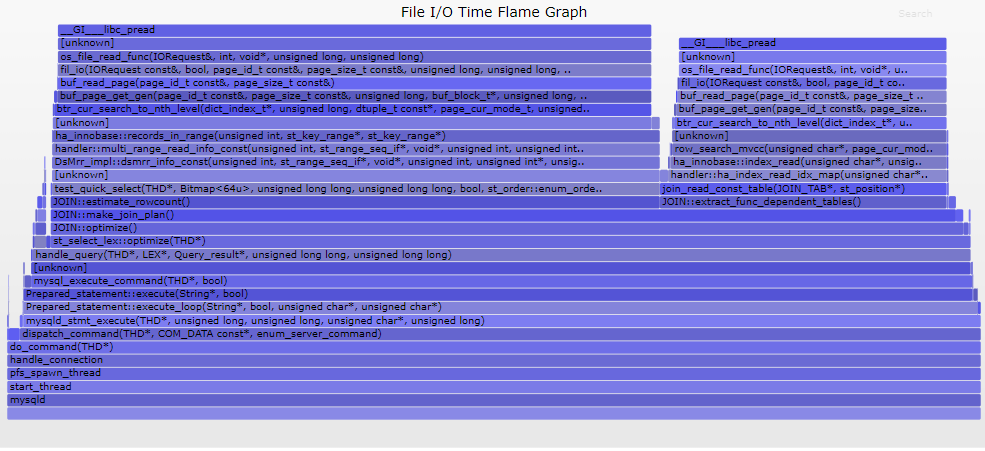
Brendan Gregg共总结了4种类型的Off-CPU火焰图:
1) I/O火焰图
File I/O或block device I/O的时间消耗:

2) Off-CPU火焰图
分析线程睡眠路径的火焰图:

3) Wakeup火焰图
分析线程被阻塞源头的火焰图:
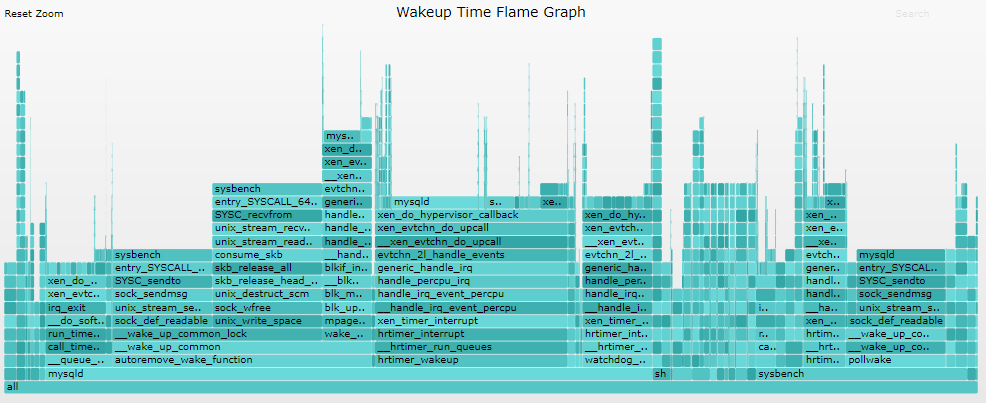
4) Chain火焰图
结合了Off-CPU和Wakeup火焰图,详细记录了线程的睡眠原因及唤醒条件:
注意:Chain火焰图性能开销巨大
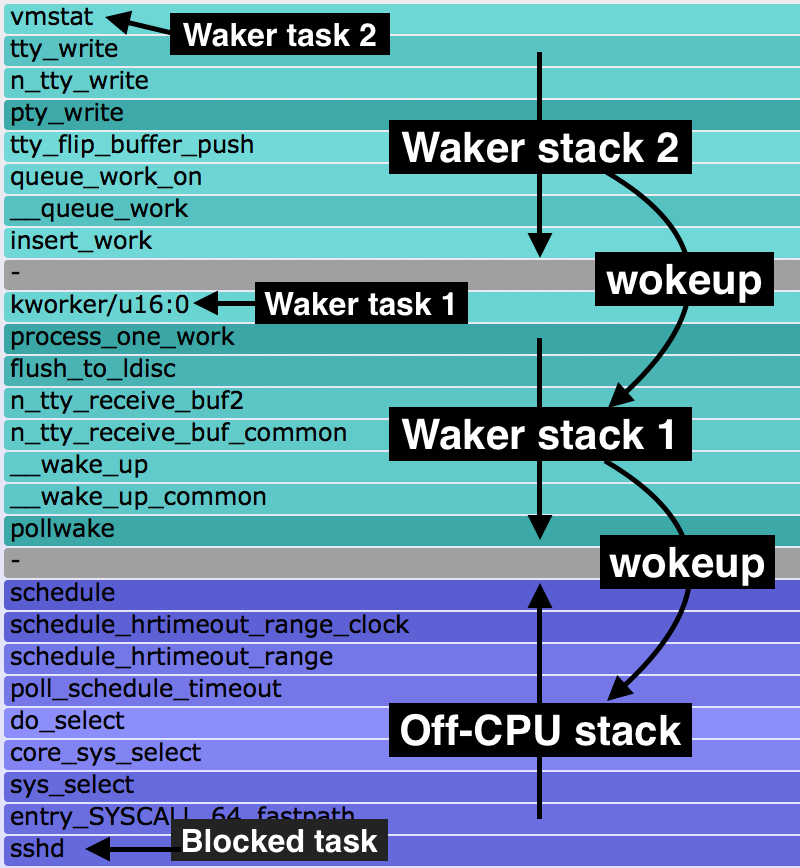
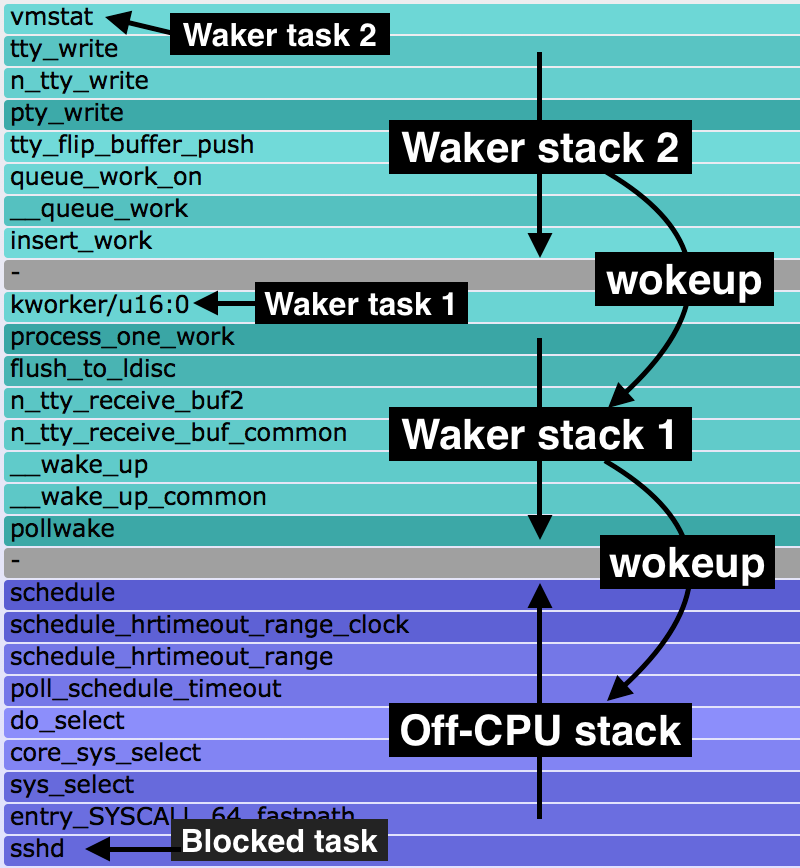
Off-CPU火焰图绘制原理
通过Off-CPU火焰图,我们可以轻松地了解系统中任何进程的睡眠过程,其原理是利用Perf Static Tracer抓取一些进程调度的相关事件,并利用Perf Inject将这些事件合并,最终得到诱发进程睡眠的调用流程以及睡眠时间。
4.8 PMU例子
例子t1和t2都比较简单,要想演示perf更加强大的能力,下面例子程序考察处理器的分支预测利用率。如前所述,分支预测能够显著提高处理器的性能,而分支预测失败则显著降低处理器的性能,首先给出一个存在BTB(Branch Target Buffers,用于记录一条分支指令的跳转地址)失效的例子:
//存在BTB失效的例子:奔腾处理器
//test.c
#include <stdio.h>
#include <stdlib.h>
void foo()
{
int i,j;
for(i=0; i<20; i++)
j+=2;
}
int main(void)
{
int i;
for(i = 0; i< 100000000; i++)
foo();
return 0;
}
gcc -o t6 -g -O0 t6.cc 用perf stat考察分支预测的使用情况:
perf stat ./t6
Performance counter stats for './t3':
6240.758394 task-clock-msecs # 0.995 CPUs
126 context-switches # 0.000 M/sec
12 CPU-migrations # 0.000 M/sec
80 page-faults # 0.000 M/sec
17683221 cycles # 2.834 M/sec (scaled from 99.78%)
10218147 instructions # 0.578 IPC (scaled from 99.83%)
2491317951 branches # 399.201 M/sec (scaled from 99.88%)
636140932 branch-misses # 25.534 % (scaled from 99.63%)
126383570 cache-references # 20.251 M/sec (scaled from 99.68%)
942937348 cache-misses # 151.093 M/sec (scaled from 99.58%)
6.271917679 seconds time elapsed
可以看到branch-misses比较严重,25%左右,Pentium4的BTB大小为16,而t6.cc中的循环迭代为20次,BTB溢出,所以处理器的分支预测将不正确。for循环编译为汇编后如下:
// C code
for ( i=0; i < 20; i++ )
{ … }
//Assembly code;
mov esi, data
mov ecx, 0
ForLoop:
cmp ecx, 20
jge
EndForLoop
…
add ecx, 1
jmp ForLoop
EndForLoop:每次循环迭代中都有一个分支语句jge,因此在运行过程中将有20次分支判断,每次分支判断都将写入BTB,但BTB是一个ring buffer,16个slot写满后便开始覆盖,如果循环迭代次数正好为16或者小于16,则完整的循环将全部写入BTB。将循环迭代次数从20减少到10,再用perf stat采样得到如下结果:
Performance counter stats for './t3:
2784.004851 task-clock-msecs # 0.927 CPUs
90 context-switches # 0.000 M/sec
8 CPU-migrations # 0.000 M/sec
81 page-faults # 0.000 M/sec
33632545 cycles # 12.081 M/sec (scaled from 99.63%)
42996 instructions # 0.001 IPC (scaled from 99.71%)
1474321780 branches # 529.569 M/sec (scaled from 99.78%)
49733 branch-misses # 0.003 % (scaled from 99.35%)
7073107 cache-references # 2.541 M/sec (scaled from 99.42%)
47958540 cache-misses # 17.226 M/sec (scaled from 99.33%)
3.002673524 seconds time elapsedbranch-misses明显减少。
5 Perf和内核
5.1 使用tracepoint
当Perf根据tick时间点进行采样后,便能够得到内核代码中hot spot,那什么时候需要使用tracepoint来采样了?人们对于tracepoint的基本需求是关心内核的运行时行为,统计相关内核函数的运行情况,内核行为对应用程序性能的影响不容忽视。下面用ls命令来演示sys_enter这个tracepoint的使用:
perf stat -e raw_syscalls:sys_enter ls
Performance counter stats for 'ls':
118 raw_syscalls:sys_enter
0.001715919 seconds time elapsed
0.000000000 seconds user
0.001381000 seconds sys
perf record -e raw_syscalls:sys_enter ls
perf report
# Samples: 70
#
# Overhead Command Shared Object Symbol
# ........ ............... ............... ......
#
97.14% ls ld-2.12.so [.] 0x0000000001629d
2.86% ls [vdso] [.] 0x00000000421424
#
# (For a higher level overview, try: perf report --sort comm,dso)
#raw_syscalls:sys_enter可以通过perf list得到,报告详细说明了ls运行期间发生了多少次系统调用(上例中118次),多数系统调用都发生在哪些地方(97.14%发生在ld-2.12.so中)。有了这个报告,或许就能发现调优的地方,对于过多的系统调用,就需要思考如何减少不必要的系统调用。
5.2 perf probe
tracepoint是静态检查点,数量有限,内核代码非常多,所以能够动态地在想查看的地方插入动态监测点很有意义。
[root@ovispoly perftest]# perf probe schedule:12 cpu
Added new event:
probe:schedule (on schedule+52 with cpu)
You can now use it on all perf tools, such as:
perf record -e probe:schedule -a sleep 1
[root@ovispoly perftest]# perf record -e probe:schedule -a sleep 1
Error, output file perf.data exists, use -A to append or -f to overwrite.
[root@ovispoly perftest]# perf record -f -e probe:schedule -a sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.270 MB perf.data (~11811 samples) ]
[root@ovispoly perftest]# perf report
# Samples: 40
#
# Overhead Command Shared Object Symbol
# ........ ............... ................. ......
#
57.50% init 0 [k] 0000000000000000
30.00% firefox [vdso] [.] 0x0000000029c424
5.00% sleep [vdso] [.] 0x00000000ca7424
5.00% perf.2.6.33.3-8 [vdso] [.] 0x00000000ca7424
2.50% ksoftirqd/0 [kernel] [k] 0000000000000000
#
# (For a higher level overview, try: perf report --sort comm,dso)
#上例利用probe命令在内核函数schedule()的第12行处添加了一个动态probe点,和tracepoint的功能一样,内核一旦运行到该probe点时,便会通知perf,可以理解为动态增加了一个新的tracepoint。此后可以用record命令的-e选项选择该probe点,最后用 perf report查看报表。
5.3 Perf sched
调度器的好坏直接影响一个系统的整体运行效率,Perf sched尝试给出调度器的评测报告,它有5个子命令:
- perf sched record # low-overhead recording of arbitrary workloads
- perf sched latency # output per task latency metrics
- perf sched map # show summary/map of context-switching
- perf sched trace # output finegrained trace
- perf sched replay # replay a captured workload using simlated threads
用户一般使用'perf sched record'收集调度相关的数据,然后就可以用'perf sched latency'查看诸如调度延迟等和调度器相关的统计数据,其他三个命令也同样读取record收集到的数据并从不同的角度来展示这些数据,下面一一进行演示:
perf sched record sleep 10
perf sched latency --sort max
-----------------------------------------------------------------------------------------------------------------
Task | Runtime ms | Switches | Average delay ms | Maximum delay ms | Maximum delay at |
-----------------------------------------------------------------------------------------------------------------
ps:20861 | 7.376 ms | 12 | avg: 0.283 ms | max: 2.774 ms | max at: 25989955.091678 s
cat:(2) | 1.546 ms | 4 | avg: 1.064 ms | max: 2.148 ms | max at: 25989950.648370 s
YDService:(13) | 24.573 ms | 590 | avg: 0.026 ms | max: 1.772 ms | max at: 25989956.645404 s
grep:(4) | 4.078 ms | 16 | avg: 0.318 ms | max: 1.397 ms | max at: 25989955.090389 s
lsblk:20854 | 3.683 ms | 9 | avg: 0.191 ms | max: 1.230 ms | max at: 25989953.649386 s
barad_agent:(10) | 42.588 ms | 478 | avg: 0.022 ms | max: 0.720 ms | max at: 25989949.645944 s
rcu_sched:9 | 1.511 ms | 198 | avg: 0.007 ms | max: 0.415 ms | max at: 25989954.355804 s
awk:(3) | 3.467 ms | 16 | avg: 0.065 ms | max: 0.341 ms | max at: 25989953.649722 s
sh:(3) | 6.957 ms | 32 | avg: 0.040 ms | max: 0.283 ms | max at: 25989953.645387 s
perf:20832 | 0.973 ms | 2 | avg: 0.115 ms | max: 0.192 ms | max at: 25989946.959473 s
trystart.sh:(2) | 3.596 ms | 20 | avg: 0.023 ms | max: 0.157 ms | max at: 25989955.099335 s
kworker/0:2:20627 | 3.066 ms | 75 | avg: 0.012 ms | max: 0.153 ms | max at: 25989952.371542 s
wc:20864 | 0.701 ms | 5 | avg: 0.036 ms | max: 0.106 ms | max at: 25989955.099355 s
jbd2/vda1-8:1221 | 0.212 ms | 4 | avg: 0.030 ms | max: 0.074 ms | max at: 25989952.375477 s
lsmd:2482 | 0.046 ms | 1 | avg: 0.049 ms | max: 0.049 ms | max at: 25989954.598457 s
systemd:(9) | 1.419 ms | 24 | avg: 0.025 ms | max: 0.048 ms | max at: 25989949.353288 s
chmod:20859 | 0.531 ms | 3 | avg: 0.022 ms | max: 0.045 ms | max at: 25989955.088030 s
ksoftirqd/0:3 | 0.462 ms | 40 | avg: 0.005 ms | max: 0.042 ms | max at: 25989947.652404 s
dirname:20858 | 0.637 ms | 5 | avg: 0.014 ms | max: 0.037 ms | max at: 25989955.087140 s
in:imjournal:18795 | 0.654 ms | 11 | avg: 0.018 ms | max: 0.031 ms | max at: 25989956.854391 s
sgagent:(2) | 0.406 ms | 5 | avg: 0.017 ms | max: 0.028 ms | max at: 25989955.100133 s
sleep:20834 | 1.274 ms | 7 | avg: 0.013 ms | max: 0.025 ms | max at: 25989956.969916 s
YDLive:(2) | 2.159 ms | 36 | avg: 0.012 ms | max: 0.019 ms | max at: 25989947.962535 s
kworker/0:1H:1174 | 0.172 ms | 5 | avg: 0.010 ms | max: 0.015 ms | max at: 25989951.363400 s
kworker/u2:0:515 | 0.325 ms | 2 | avg: 0.009 ms | max: 0.013 ms | max at: 25989955.043431 s
watchdog/0:11 | 0.000 ms | 2 | avg: 0.011 ms | max: 0.011 ms | max at: 25989949.766375 s
kworker/0:1:19712 | 0.956 ms | 5 | avg: 0.001 ms | max: 0.001 ms | max at: 25989956.403608 s
-----------------------------------------------------------------------------------------------------------------
TOTAL: | 113.368 ms | 1607 |
---------------------------------------------------各column的含义如下:
- Task:进程的名字和pid;
- Runtime:实际运行时间;
- Switches:进程切换的次数;
- Average delay:平均的调度延迟;
- Maximum:最大延迟;
最值得关注的是Maximum delay,一般从这里可以看到对交互性影响最大的特性:调度延迟,如果调度延迟比较大,那么用户就会感受到视频或者音频断断续续。
下面演示map:
[root@VM_100_12_centos ~]# perf sched map
*A0 25989946.959281 secs A0 => perf:20834
*B0 25989946.959342 secs B0 => rcu_sched:9
*C0 25989946.959345 secs C0 => ksoftirqd/0:3
*B0 25989946.959351 secs
*A0 25989946.959353 secs
*D0 25989946.959473 secs D0 => perf:20832
*. 25989946.959516 secs . => swapper:0
*B0 25989946.960345 secs
*C0 25989946.960349 secs
*B0 25989946.960355 secs
*. 25989946.960358 secs
*B0 25989946.961336 secs
*. 25989946.961339 secs
*E0 25989946.962304 secs E0 => YDLive:6722
*. 25989946.962355 secs
*F0 25989946.965981 secs F0 => barad_agent:27676
*. 25989946.966044 secs
*A0 25989946.967405 secs
*. 25989946.967783 secs
*A0 25989946.969034 secs A0 => sleep:20834
*G0 25989946.969114 secs G0 => YDService:31411
*A0 25989946.969138 secs
*B0 25989946.969347 secs
*A0 25989946.969351 secs
*. 25989946.969559 secs
*B0 25989946.970348 secs
*. 25989946.970354 secs
*B0 25989946.971341 secs
*. 25989946.971345 secs
*B0 25989946.972337 secs
*. 25989946.972341 secs
*H0 25989946.973412 secs H0 => YDService:31000
*. 25989946.973426 secs
*I0 25989946.978006 secs I0 => YDService:30999
*. 25989946.978017 secs
*J0 25989946.998375 secs J0 => kworker/0:2:20627
*. 25989946.998398 secs
*K0 25989947.005190 secs K0 => YDService:31394
*. 25989947.005210 secs
*L0 25989947.008986 secs L0 => YDService:31395
*. 25989947.009004 secs
*F0 25989947.016115 secs
星号表示调度事件发生所在的CPU,点号表示CPU正在IDLE。Map的好处在于提供了一个总的视图:将成百上千的调度事件进行总结,显示了系统任务在CPU之间的分布,假如有不好的调度迁移,比如一个任务没有被及时迁移到idle的CPU,却被迁移到其他忙碌的CPU,类似这种调度器的问题可以从map的报告中看出来。如果说map提供了高度概括的总体报告,那么trace就提供了最详细、最底层的细节报告:
pipe-test-100k-13520 [001] 1254.354513808: sched_stat_wait:
task: pipe-test-100k:13521 wait: 5362 [ns]
pipe-test-100k-13520 [001] 1254.354514876: sched_switch:
task pipe-test-100k:13520 [120] (S) ==> pipe-test-100k:13521 [120]
:13521-13521 [001] 1254.354517927: sched_stat_runtime:
task: pipe-test-100k:13521 runtime: 5092 [ns], vruntime: 133967391150 [ns]
:13521-13521 [001] 1254.354518984: sched_stat_sleep:
task: pipe-test-100k:13520 sleep: 5092 [ns]
:13521-13521 [001] 1254.354520011: sched_wakeup:
task pipe-test-100k:13520 [120] success=1 [001]要理解以上的信息,必须对调度器的源代码有一定了解。
Perf replay更是专门为调度器开发人员所设计,它试图重放perf.data文件中所记录的调度场景。很多情况下,一般用户如果发现调度器的奇怪行为,他们也无法准确描述发生该情形的场景,或者一些测试场景不容易重现,使用perf replay将模拟perf.data中的场景,无需开发人员花费很多的时间去重现问题,这尤其利于调试过程:
[root@VM_100_12_centos ~]# perf sched replay
run measurement overhead: 471 nsecs
sleep measurement overhead: 36317 nsecs
the run test took 999982 nsecs
the sleep test took 1078878 nsecs
nr_run_events: 2685
nr_sleep_events: 2818
nr_wakeup_events: 1461
task 0 ( swapper: 0), nr_events: 3308
task 1 ( swapper: 1), nr_events: 33
task 2 ( :2: 2), nr_events: 1
task 3 ( :10: 10), nr_events: 1
task 4 ( :104: 104), nr_events: 1
task 5 ( :11: 11), nr_events: 5
task 6 ( :1174: 1174), nr_events: 11
task 7 ( :1221: 1221), nr_events: 10
task 8 ( :1222: 1222), nr_events: 1
task 9 ( :13: 13), nr_events: 1
task 10 ( systemd: 1326), nr_events: 1
task 11 ( systemd: 1334), nr_events: 1
task 12 ( systemd: 13837), nr_events: 1
task 13 ( :14: 14), nr_events: 1
task 14 ( :15: 15), nr_events: 1
task 15 ( :16: 16), nr_events: 1
task 16 ( :17: 17), nr_events: 1
task 17 ( :18: 18), nr_events: 1
task 18 ( :2867: 2867), nr_events: 1
task 19 ( :18546: 18546), nr_events: 1
task 20 ( sshd: 18580), nr_events: 1
task 21 ( systemd: 18714), nr_events: 1
task 22 ( rsyslogd: 18795), nr_events: 23
task 23 ( rsyslogd: 19420), nr_events: 1
task 24 ( :18796: 18796), nr_events: 1
task 25 ( :19: 19), nr_events: 1
task 26 ( :19712: 19712), nr_events: 16
task 27 ( kthreadd: 20), nr_events: 1
task 28 ( kthreadd: 20627), nr_events: 156
task 29 ( bash: 20832), nr_events: 6
task 30 ( perf: 20834), nr_events: 21
task 31 ( kthreadd: 21), nr_events: 1
task 32 ( kthreadd: 22), nr_events: 1
task 33 ( kthreadd: 23), nr_events: 1
task 34 ( systemd: 2373), nr_events: 1
task 35 ( auditd: 2374), nr_events: 1
task 36 ( kthreadd: 24), nr_events: 1
task 37 ( systemd: 2466), nr_events: 1
task 38 ( systemd: 2471), nr_events: 1
task 39 ( systemd: 2474), nr_events: 1
task 40 ( systemd: 2480), nr_events: 1
task 41 ( polkitd: 2520), nr_events: 15.4 Perf bench
除调度器之外,很多时候人们都需要衡量自己的工作对系统性能的影响,benchmark是衡量性能的标准方法,我机器上提供了以下几种benchmark:
sched: Scheduler and IPC benchmarks
mem: Memory access benchmarks
numa: NUMA scheduling and MM benchmarks
futex: Futex stressing benchmarks
all: All benchmarks例子:
1) Sched message
[lm@ovispoly ~]$ perf bench sched messaging
# Running sched/messaging benchmark...# 20 sender and receiver processes per group# 10 groups == 400 processes run Total time: 1.918 [sec]sched message 是从经典的测试程序hackbench移植而来,用来衡量调度器的性能,overhead以及可扩展性。该benchmark启动N个 reader/sender进程或线程对,通过IPC(socket或者pipe)进行并发读写。一般人们将N不断加大来衡量调度器的可扩展性。
2) Sched Pipe
[lm@ovispoly ~]$ perf bench sched pipe
# Running sched/pipe benchmark...# Extecuted 1000000 pipe operations between two tasks Total time: 20.888 [sec] 20.888017 usecs/op 47874 ops/secsched pipe从Ingo Molnar的pipe-test-1m.c移植而来,Ingo原始程序是为了测试不同调度器的性能和公平性的,其工作原理很简单:两个进程互相通过pipe拼命地发1000000个整数,进程A发给B,同时B发给A,因为A和B互相依赖,因此如果调度器不公平,对A比 B好,那么A和B整体所需要的时间就会更长。
3) Mem memcpy
[lm@ovispoly ~]$ perf bench mem memcpy
# Running mem/memcpy benchmark...# Copying 1MB Bytes from 0xb75bb008 to 0xb76bc008 ... 364.697301 MB/Sec这个是perf bench的作者Hitoshi Mitake自己写的一个执行memcpy的 benchmark,该测试衡量拷贝1M数据的memcpy()函数所花费的时间。
5.5 Perf lock
锁是内核同步的方法,一旦加了锁,其他准备加锁的内核执行路径就必须等待,降低了并行。因此对于锁进行专门分析是调优的一项重要工作:
Name acquired contended total wait (ns) max wait (ns) min
&md->map_lock 396 0 0 0
&(&mm->page_tabl... 309 0 0 0
&(&tty->buf.lock... 218 0 0 0
&ctx->lock 185 0 0 0
key 178 0 0 0
&ctx->lock 132 0 0 0
&tty->output_loc... 126 0 0 0
...
&(&object->lock)... 1 0 0 0
&(&object->lock)... 0 0 0 0
&(&object->lock)... 0 0 0 0
&p->cred_guard_m... 0 0 0 0
=== output for debug===
bad: 28, total: 664
bad rate: 4.216867 %
histogram of events caused bad sequence
acquire: 8
acquired: 0
contended: 0
release: 20"Name": 锁的名字,比如md->map_lock,即定义在dm.c结构mapped_device中的读写锁;
"acquired": 该锁被直接获得的次数,即没有其他内核路径拥有该锁的情况下得到该锁的次数;
"contended":冲突的次数,即在准备获得该锁的时候已经被其他人所拥有的情况的出现次数;
"total wait":为了获得该锁,总共的等待时间;
"max wait":为了获得该锁,最大的等待时间;
"min wait":为了获得该锁,最小的等待时间;
5.6 Perf Kmem
Perf Kmem专门收集内核slab分配器的相关事件,比如内存分配释放等,可以用来研究程序在哪里分配了大量内存,或者在什么地方产生碎片等内存管理相关的问题。Perf kmem和perf lock实际上都是perf tracepoint的特例,您也完全可以用Perf record -e kmem:* 或者perf record -e lock:*来完成同样的功能。Perf kmem的输出结果如下:
perf kmem record OR perf record -e kmem:*
perf kmem --alloc -l 10 --caller stat
Check IO/CPU overload!
---------------------------------------------------------------------------------------------------------
Callsite | Total_alloc/Per | Total_req/Per | Hit | Ping-pong | Frag
---------------------------------------------------------------------------------------------------------
mem_cgroup_css_alloc+11a | 4096/4096 | 2080/2080 | 1 | 0 | 49.219%
sk_prot_alloc+c3 | 47104/2048 | 24472/1064 | 23 | 1 | 48.047%
do_seccomp+2af | 1024/1024 | 544/544 | 1 | 0 | 46.875%
alloc_fair_sched_group+b5 | 2048/512 | 1152/288 | 4 | 0 | 43.750%
cgroup_alloc_name.isra.23+1f | 192/64 | 111/37 | 3 | 0 | 42.188%
cgroup_release_agent+85 | 64/64 | 39/39 | 1 | 0 | 39.062%
proc_reg_open+32 | 2304/64 | 1440/40 | 36 | 0 | 37.500%
alloc_pipe_info+e3 | 20480/1024 | 12800/640 | 20 | 1 | 37.500%
key_alloc+12d | 8/8 | 5/5 | 1 | 0 | 37.500%
pskb_expand_head+6a | 22016/1000 | 13824/628 | 22 | 0 | 37.209%
assoc_array_clear+29 | 512/512 | 328/328 | 1 | 0 | 35.938%
assoc_array_insert+56 | 512/512 | 328/328 | 1 | 0 | 35.938%
sk_chk_filter+12e | 192/192 | 130/130 | 1 | 0 | 32.292%
sched_create_group+25 | 4096/1024 | 2816/704 | 4 | 0 | 31.250%
__d_alloc+145 | 384/64 | 270/45 | 6 | 0 | 29.688%
seq_open+106 | 62976/192 | 44608/136 | 328 | 0 | 29.167%
allocate_cg_links+55 | 3072/64 | 2304/48 | 48 | 0 | 25.000%
proc_self_follow_link+66 | 576/16 | 432/12 | 36 | 0 | 25.000%
alloc_pipe_info+3d | 3840/192 | 2880/144 | 20 | 0 | 25.000%
kernfs_fop_open+1c5 | 1088/64 | 816/48 | 17 | 0 | 25.000%
alloc_rt_sched_group+139 | 384/96 | 288/72 | 4 | 0 | 25.000%
alloc_fdtable+57 | 192/64 | 144/48 | 3 | 0 | 25.000%
bio_alloc_map_data+93 | 96/32 | 72/24 | 3 | 0 | 25.000%
ext4_readdir+732 | 128/64 | 96/48 | 2 | 0 | 25.000%
scm_fp_dup+28 | 64/32 | 48/24 | 2 | 0 | 25.000%
___sys_sendmsg+25e | 192/192 | 144/144 | 1 | 0 | 25.000%
__alloc_skb+8d | 349696/863 | 262848/649 | 405 | 5 | 24.835%
_autofs_dev_ioctl+d0 | 384/48 | 292/36 | 8 | 0 | 23.958%
load_elf_interp.constprop.10+84 | 8704/512 | 6664/392 | 17 | 0 | 23.438%
groups_alloc+34 | 1152/192 | 912/152 | 6 | 0 | 20.833%
assoc_array_insert+28e | 192/192 | 152/152 | 1 | 0 | 20.833%
cgroup_mkdir+56 | 1536/512 | 1224/408 | 3 | 0 | 20.312%
take_dentry_name_snapshot+a6 | 128/64 | 103/51 | 2 | 0 | 19.531%
virtqueue_add+1c4 | 1873664/603 | 1541600/496 | 3105 | 43 | 17.723%
----------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------
Alloc Ptr | Total_alloc/Per | Total_req/Per | Hit | Ping-pong | Frag
---------------------------------------------------------------------------------------------------------
0xffff9f67bc71ce00 | 1024/512 | 544/272 | 2 | 0 | 46.875%
0xffff9f67bc652000 | 16384/8192 | 8832/4416 | 2 | 0 | 46.094%
0xffff9f67bd7f1c00 | 5120/1024 | 2800/560 | 5 | 0 | 45.312%
0xffff9f6783ccb000 | 2048/2048 | 1152/1152 | 1 | 0 | 43.750%
0xffff9f67b60ccc00 | 2048/1024 | 1168/584 | 2 | 0 | 42.969%
0xffff9f67bbe02800 | 1536/512 | 880/293 | 3 | 0 | 42.708%
0xffff9f67b656e800 | 1536/512 | 896/298 | 3 | 0 | 41.667%
0xffff9f67bc7d9c00 | 5120/1024 | 3008/601 | 5 | 0 | 41.250%
0xffff9f678a3e8800 | 2048/2048 | 1216/1216 | 1 | 0 | 40.625%
0xffff9f67bc1f0800 | 17408/1024 | 10552/620 | 17 | 0 | 39.384%
... | ... | ... | ... | ... | ...
---------------------------------------------------------------------------------------------------------
SUMMARY (SLAB allocator)
========================
Total bytes requested: 156,708,061
Total bytes allocated: 157,232,192
Total bytes freed: 141,407,016
Net total bytes allocated: 15,825,176
Total bytes wasted on internal fragmentation: 524,131
Internal fragmentation: 0.333348%
Cross CPU allocations: 1,202/1,813,162
该报告有三个部分:Callsite,所谓Callsite即内核代码中调用kmalloc和kfree的地方。比如上图中的函数proc_reg_open,Hit 栏为36,表示该函数在record期间一共调用kmalloc 36次,virtqueue_add对应的hit栏数字为3105,则表示函数 virtqueue_add共有3105次调用kmalloc分配内存。
对于第一行Total_alloc/Per显示为4096/4096,第一个值4096表示函数mem_cgroup_css_alloc总共分配的内存大小,Per表示平均值。
比较有趣的两个参数是Ping-pong和Frag。Frag比较容易理解,即内部碎片,虽然相对于Buddy System,Slab正是要解决内部碎片问题,但slab依然存在内部碎片,比如一个cache的大小为1024,但需要分配的数据结构大小为1022,那么有2个字节成为碎片,Frag即碎片的比例。
Ping-pong是一种现象,在多CPU系统中,多个CPU共享的内存会出现"乒乓现象":一个CPU分配内存,其他CPU可能访问该内存对象,也可能最终由另外一个CPU释放该内存对象,而在多CPU系统中,L1 cache是per CPU的,CPU2修改了内存,那么其他CPU的cache都必须更新,这对于性能是一个损失。Perf kmem在kfree事件中判断CPU号,如果和kmalloc时的不同,则视为一次ping-pong,理想的情况下ping-pone 越小越好。
接着则是根据被调用地点的显示方式的部分。
最后一部分是汇总数据,显示总的分配的内存和碎片情况,Cross CPU allocation 即ping-pong的汇总。
5.7 Perf timechart
很多perf命令都是为调试单个程序或者单个目的而设计,但有时候性能问题并非由单个原因所引起,需要从各个角度一一查看,为此,人们常需要综合利用各种工具,比如top,vmstat,oprofile或者perf,这非常麻烦。此外,前面介绍的所有工具都是基于命令行的,报告不够直观,更令人气馁的是,一些报告中的参数令人费解。perf timechart采用"简单"的图形"一目了然"地揭示问题所在:perf timechart。Timechart可以显示更详细的信息,perf timechart生成的实际上是一个矢量图形svg格式,用SVG viewer的放大功能,我们可以将该图的细节部分放大,timechart的设计理念叫做"infinitely zoomable"。
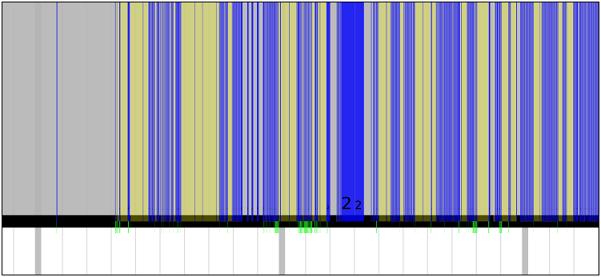
上图中需要注意的是几条绿色的短线,表示进程通信,即准备绘图。假如通信的两个进程在图中上下相邻,那么绿线可以连接他们。但如果不相邻,则只会显示如上图所示的被截断的绿色短线。蓝色部分表示进程忙碌,黄色部分表示该进程的时间片已经用完,但仍处于就绪状态,在等待调度器分配CPU。通过这张图,便可以较直观地看到进程在一段时间内的详细行为。
perf timechart record cat /dev/zero > /dev/null
perf timechart -i perf.data #生成output.svg6 使用script增强perf的功能
perf的输出虽然是文本格式,但还是不太容易分析和阅读,需要进一步处理,perl和python是目前最强大的两种脚本语言。Tom Zanussi将perl和python解析器嵌入到perf程序中,从而使得perf能够自动执行perl或者python脚本进一步进行处理,从而为perf 提供了强大的扩展能力。
7 实例
7.1 统计系统中进入S状态的进程的睡眠时长及原因
root@node10:/home$ echo 1 >/proc/sys/kernel/sched_schedstats
root@node10:/home$ perf record -e sched:sched_stat_sleep -e sched:sched_switch -a -g -o perf.data.raw sleep 1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.430 MB perf.data.raw (1031 samples) ]
root@node10:/home$ perf inject -s -v -i perf.data.raw -o perf.data
build id event received for [kernel.kallsyms]: f63207ec0e8d394d5a860306746f9064bfd0290a
symsrc__init: cannot get elf header.
Looking at the vmlinux_path (7 entries long)
Using /proc/kcore for kernel object code
Using /proc/kallsyms for symbols通过追踪sched_switch事件获取相关进程切换的调用栈;通过追踪sched_stat_sleep事件获取进程的睡眠时间,最后利用Perf Inject合并两个事件即可,下面我们看看合并过程:
1) 首先查看合并前的事件:
root@node10:/home$ perf script -i perf.data.raw -F comm,pid,tid,cpu,time,period,event,ip,sym,dso,trace
...
client 2344/2345 [007] 342165.258739: 1 sched:sched_switch: prev_comm=client prev_pid=2345 prev_prio=120 prev_state=S ==> next_comm=swapper/7 next_pid=0 next_prio=120
7fff8168dbb0 __schedule ([kernel.kallsyms])
7fff8168e069 schedule ([kernel.kallsyms])
7fff8168d0f2 schedule_hrtimeout_range_clock ([kernel.kallsyms])
7fff8168d1a3 schedule_hrtimeout_range ([kernel.kallsyms])
7fff81215215 poll_schedule_timeout ([kernel.kallsyms])
7fff81215b91 do_select ([kernel.kallsyms])
7fff81215e5b core_sys_select ([kernel.kallsyms])
7fff812162af sys_pselect6 ([kernel.kallsyms])
7fff81699089 system_call_fastpath ([kernel.kallsyms])
1cc4e3 runtime.usleep (/usr/local/gundam/gundam_client/client)
1aac33 runtime.sysmon (/usr/local/gundam/gundam_client/client)
1373300000500 [unknown] ([unknown])
58b000003d98f0f [unknown] ([unknown])
...
swapper 0/0 [007] 342165.260097: 1358063 sched:sched_stat_sleep: comm=client pid=2345 delay=1358063 [ns]
7fff810d2a40 enqueue_entity ([kernel.kallsyms])
7fff810d2f59 enqueue_task_fair ([kernel.kallsyms])
7fff810bf481 enqueue_task ([kernel.kallsyms])
7fff810c3dc3 activate_task ([kernel.kallsyms])
7fff810c4103 ttwu_do_activate.constprop.91 ([kernel.kallsyms])
7fff810c72e9 try_to_wake_up ([kernel.kallsyms])
7fff810c7483 wake_up_process ([kernel.kallsyms])
7fff810b6662 hrtimer_wakeup ([kernel.kallsyms])
7fff810b6d72 __hrtimer_run_queues ([kernel.kallsyms])
7fff810b7310 hrtimer_interrupt ([kernel.kallsyms])
7fff81052fd7 local_apic_timer_interrupt ([kernel.kallsyms])
7fff8169b78f smp_apic_timer_interrupt ([kernel.kallsyms])
7fff81699cdd apic_timer_interrupt ([kernel.kallsyms])
7fff81516a69 cpuidle_idle_call ([kernel.kallsyms])
7fff810370ee arch_cpu_idle ([kernel.kallsyms])
7fff810ea2a5 cpu_startup_entry ([kernel.kallsyms])
7fff8105107a start_secondary ([kernel.kallsyms])
...2) 合并后的事件:
root@node10:/home$ perf script -i perf.data -F comm,pid,tid,cpu,time,period,event,ip,sym,dso,trace
...
client 2344/2345 [007] 342165.260097: 1358063 sched:sched_switch: prev_comm=client prev_pid=2345 prev_prio=120 prev_state=S ==> next_comm=swapper/7 next_pid=0 next_prio=120
7fff8168dbb0 __schedule ([kernel.kallsyms])
7fff8168e069 schedule ([kernel.kallsyms])
7fff8168d0f2 schedule_hrtimeout_range_clock ([kernel.kallsyms])
7fff8168d1a3 schedule_hrtimeout_range ([kernel.kallsyms])
7fff81215215 poll_schedule_timeout ([kernel.kallsyms])
7fff81215b91 do_select ([kernel.kallsyms])
7fff81215e5b core_sys_select ([kernel.kallsyms])
7fff812162af sys_pselect6 ([kernel.kallsyms])
7fff81699089 system_call_fastpath ([kernel.kallsyms])
1cc4e3 runtime.usleep (/usr/local/gundam/gundam_client/client)
1aac33 runtime.sysmon (/usr/local/gundam/gundam_client/client)
1373300000500 [unknown] ([unknown])
58b000003d98f0f [unknown] ([unknown])
...7.2 分析CPU使用率
1) 模拟CPU利用率暴涨的现象:
cat /dev/zero > /dev/null可以看到CPU的%system飙升至95%:
sar -P ALL -u 1 100
05:13:57 PM CPU %user %nice %system %iowait %steal %idle
05:13:58 PM all 2.00 0.00 98.00 0.00 0.00 0.00
05:13:58 PM 0 2.00 0.00 98.00 0.00 0.00 0.002) Perf工具采样
[root@VM_100_12_centos ~]# perf record -a -e cycles -o cycle.perf -g sleep 10
[ perf record: Woken up 6 times to write data ]
[ perf record: Captured and wrote 1.402 MB cycle.perf (10002 samples) ]"-a"表示对所有CPU采样,如果只需针对特定的CPU,可以使用"-C"选项。
3) 采样数据生成报告
# perf report -i cycle.perf | more
...
# Samples: 40K of event 'cycles'
# Event count (approx.): 18491174032
#
# Overhead Command Shared Object Symbol
# ........ ............... .............................. ................
#
75.65% cat [kernel.kallsyms] [k] __clear_user
|
--- __clear_user
|
|--99.56%-- read_zero
| vfs_read
| sys_read
| system_call_fastpath
| __GI___libc_read
--0.44%-- [...]
2.34% cat [kernel.kallsyms] [k] system_call
|
--- system_call
|
|--56.72%-- __write_nocancel
|
--43.28%-- __GI___libc_read
...我们很清楚地看到,CPU利用率有75%来自cat进程的sys_read系统调用,perf甚至精确地告诉了我们是消耗在read_zero这个 kernel routine上。
7.3 统计系统调用
下面的命令统计所有调用次数大于0的系统调用的数量:
[root@VM_100_12_centos test]# perf stat -e 'syscalls:sys_enter_*' ls 2>&1 | awk '$1 != 0'
Performance counter stats for 'ls':
2 syscalls:sys_enter_statfs
2 syscalls:sys_enter_getdents
2 syscalls:sys_enter_ioctl
1 syscalls:sys_enter_newstat
12 syscalls:sys_enter_newfstat
10 syscalls:sys_enter_read
1 syscalls:sys_enter_write
2 syscalls:sys_enter_access
11 syscalls:sys_enter_open
1 syscalls:sys_enter_openat
14 syscalls:sys_enter_close
18 syscalls:sys_enter_mprotect
3 syscalls:sys_enter_brk
3 syscalls:sys_enter_munmap
1 syscalls:sys_enter_set_robust_list
1 syscalls:sys_enter_getrlimit
1 syscalls:sys_enter_rt_sigprocmask
2 syscalls:sys_enter_rt_sigaction
1 syscalls:sys_enter_exit_group
1 syscalls:sys_enter_set_tid_address
28 syscalls:sys_enter_mmap
0.002270896 seconds time elapsed
0.001741000 seconds sys
使用strace命令可以获得类似的结果,但是strace的成本要高的多,测试结果显示,perf可能让程序变慢2.5倍,而strace则会让程序变慢高达60倍。
7.4 统计新建进程
[root@VM_100_12_centos test]# perf record -e sched:sched_process_exec -a
# Ctrl-C
[root@VM_100_12_centos test]# perf report -n --sort comm --stdio
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 8 of event 'sched:sched_process_exec'
# Event count (approx.): 8
#
# Overhead Samples Command
# ........ ............ .......
#
25.00% 2 awk
25.00% 2 cat
25.00% 2 grep
25.00% 2 sh
#
# (Tip: If you have debuginfo enabled, try: perf report -s sym,srcline)
#追踪点sched:sched_process_exec在某个进程调用exec()产生另外一个进程时生效,这通常是新进程的产生方式,但是这个例子的结果不一定准确,原因是:
- 进程可能fork()出子进程,追踪点sched:sched_process_fork可以用于这种情况;
- 应用程序可以reexec -- 针对自己再次调用exec() -- 这种用法可以清空地址空间,但是不会产生新进程;
7.5 追踪出站连接
某些时候你希望了解服务器发起了哪些网络连接,是哪些进程发起的,为何发起,这些网络连接可能是延迟的根源。追踪connect系统调用,即可了解出站连接:
perf record -e syscalls:sys_enter_connect -ag
perf report --stdio
# Children Self Trace output
# ........ ........ ............................................................
#
5.88% 5.88% fd: 0x00000005, uservaddr: 0xc4206fa390, addrlen: 0x0000001b
|
---0x894812ebc0312874
0xc42008e000
runtime.main
main.main
github.com/projectcalico/node/pkg/readiness.Run
github.com/projectcalico/node/pkg/readiness.checkBIRDReady
github.com/projectcalico/node/pkg/readiness/bird.GRInProgress
net.Dial
net.(*Dialer).Dial
net.(*Dialer).DialContext
net.dialSerial
net.dialSingle
net.dialUnix
net.unixSocket
net.socket
net.(*netFD).dial
net.(*netFD).connect
syscall.Connect
syscall.Syscall
可以看到,占比最高的出站连接是由Calico Node容器发起的。
7.6 追踪套接字缓冲
通过剖析套接字缓冲的使用情况,也是定位什么代码使用了最多的网络I/O的一种方法:
perf record -e 'skb:consume_skb' -ag7.7 睡眠时间分析
使用perf可以了解应用程序为何修改、在何处休眠、休眠多久,主要通过收集sched_stat、sched_switch事件实现。
#include <time.h>
#include <sys/select.h>
#include <sys/time.h>
using namespace std;
int main(int argc, char** argv)
{
struct timespec ts1;
struct timeval tv1;
for (int i = 0; i < 10; i++) {
ts1.tv_sec = 0;
ts1.tv_nsec = 10000000;
// 休眠
nanosleep(&ts1, NULL);
tv1.tv_sec = 0;
tv1.tv_usec = 40000;
// 休眠
select(0, NULL, NULL, NULL,&tv1);
}
return 0;
}
g++ -o t5 -g t5.cc
perf record -e sched:sched_stat_sleep -e sched:sched_switch -e sched:sched_process_exit -g -o perf.data.raw ./t5合并sched_start、sched_switch事件:
perf inject -v -s -i perf.data.raw -o perf.data报告:
perf report --stdio --show-total-period -i perf.data
100.00% 502408738 foo [kernel.kallsyms] [k] __schedule
|
--- __schedule
schedule
|
|--79.85%-- schedule_hrtimeout_range_clock
| schedule_hrtimeout_range
| poll_schedule_timeout
| do_select
| core_sys_select
| sys_select
| system_call_fastpath
| __select
| __libc_start_main
|
--20.15%-- do_nanosleep
hrtimer_nanosleep
sys_nanosleep
system_call_fastpath
__GI___libc_nanosleep
__libc_start_main7.8 CPU性能火焰图
用Perf统计命令:dd if=/dev/zero of=/dev/null count=1000000
[root@VM_100_12_centos test]# perf stat dd if=/dev/zero of=/dev/null count=1000000
1000000+0 records in
1000000+0 records out
512000000 bytes (512 MB) copied, 0.569784 s, 899 MB/s
Performance counter stats for 'dd if=/dev/zero of=/dev/null count=1000000':
565.99 msec task-clock # 0.991 CPUs utilized
66 context-switches # 0.117 K/sec
0 cpu-migrations # 0.000 K/sec
219 page-faults # 0.387 K/sec
1,309,932,486 cycles # 2.314 GHz (66.83%)
138,684,063 stalled-cycles-frontend # 10.59% frontend cycles idle (66.88%)
270,766,379 stalled-cycles-backend # 20.67% backend cycles idle (66.33%)
2,123,756,264 instructions # 1.62 insn per cycle
# 0.13 stalled cycles per insn (66.31%)
399,698,369 branches # 706.197 M/sec (66.84%)
7,160,104 branch-misses # 1.79% of all branches (66.81%)
0.570944554 seconds time elapsed
0.108440000 seconds user
0.457861000 seconds sys
perf report -n --stdio -i perf.data结果不易阅读,下面生成火焰图分析:
perf record -F 99 -g dd if=/dev/zero of=/dev/null count=100000000 OR perf record -g cat /dev/zero > /dev/null
#指定进程PID:perf record -g -p 11493 -- sleep 60
perf script -i perf.data > out.perf通常的做法是将out.perf拷贝到本地机器,在本地生成火焰图:
git clone --depth 1 https://github.com/brendangregg/FlameGraph.git
#折叠调用栈
FlameGraph/stackcollapse-perf.pl out.perf > out.folded
#生成火焰图
FlameGraph/flamegraph.pl out.folded > out.svg生成火焰图可以指定参数,–width指定图片宽度,–height指定每一个调用栈的高度,生成的火焰图,宽度越大就表示CPU耗时越多。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至yj.mapple@gmail.com
文章标题:perf性能分析
文章字数:12k
本文作者:melonshell
发布时间:2019-10-09, 07:54:19
最后更新:2019-11-01, 10:21:33
原始链接:http://melonshell.github.io/2019/10/09/tool1_perf/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

